12 mins
Wholesale Colocation for AI Workloads: Power Density, Cooling, and Deployment Considerations
Wholesale colocation for AI workloads in 2026 is a supply-and-terms problem: capacity above 5 MW is largely booked through 2028, and the 1 to 5 MW envelope that remains is not publicly indexed. The buyer's decision is less about real estate and more about which market still has capacity, which provider will negotiate, and which deployment model fits the GPU timeline.

The macro picture is consistent across every primary AI market. 5 MW and larger blocks have been pre-committed by hyperscalers, neoclouds, and AI labs through 2028, the 1 to 5 MW capacity that remains is findable only through providers willing to surface inventory that does not sit on a public listing, providers have hardened commercial terms over the past 18 months around larger upfront commitments and 3 to 5 year minimums, and GPU density inside the four walls continues to drive hall-level cooling and substation sizing.
This guide treats the wholesale AI colocation decision as three problems in sequence: a market problem (where can the capacity be sourced), a workload problem (how does what you are doing translate into rack, hall, and campus power), and a contract problem (which terms can be negotiated and which cannot).
What is Wholesale Colocation
Wholesale colocation is dedicated, separately metered data center capacity sold in multi-megawatt blocks, distinguished from retail colocation and traditional enterprise data centers by five dimensions: capacity threshold (500 kW at the lowest provider floor, 1 MW or more at most), term length (3 to 10+ years versus 1 to 3 for retail), deployment model (build-to-suit, powered shell, or turnkey, versus rack-and-stack), lead time (12 to 36 months versus weeks), and buyer type (AI labs, hyperscalers, neoclouds, and large enterprises versus IT departments). Wholesale data centers, in other words, are a different product engineered for a different procurement cycle, not just a bigger version of retail colocation.
The buyer set has widened materially since 2023: what was a hyperscaler and tier-one AI lab market three years ago now includes neoclouds (CoreWeave, Crusoe, Lambda, Nscale), sovereign AI buyers in the EU, Middle East, and Asia, and large enterprises standing up in-house AI training or production inference. More buyers chasing finite inventory is why 2026 procurement plays out very differently from 2023.
The Wholesale AI Capacity Supply Reality in 2026
The wholesale AI capacity market in 2026 is shaped by three constraints that buyers consistently underestimate at the start of a sourcing process: 5 MW and larger blocks have been pre-committed through 2028 in every primary metro, 1 to 5 MW capacity remains findable but is not publicly indexed, and grid interconnection has become the upstream bottleneck even when the building itself exists. The combination determines which deals are achievable on which timeline.
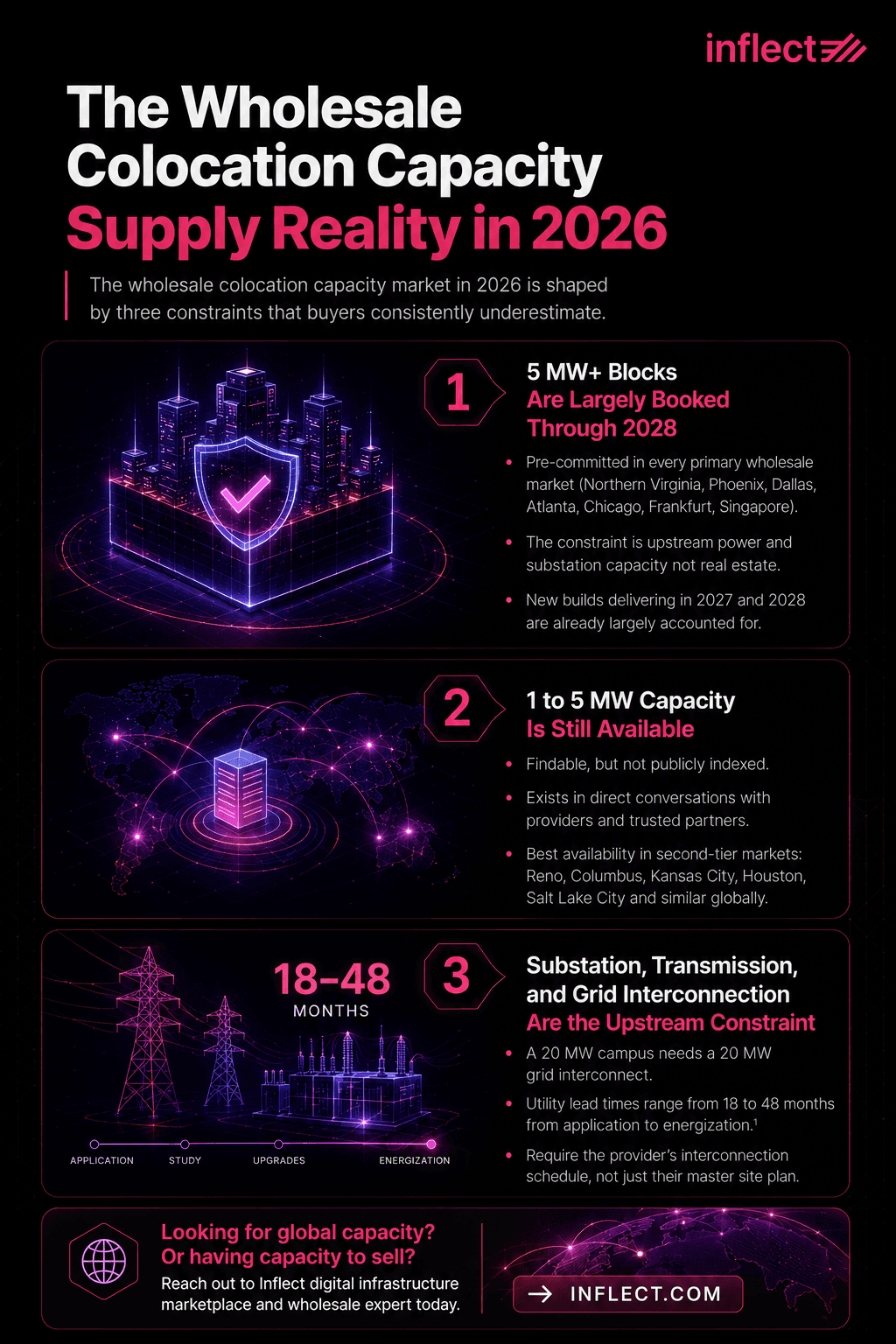
Why 5 MW+ Blocks Are Largely Booked Through 2028
Capacity at 5 MW per deployment and above has been pre-committed in nearly every primary wholesale market (Northern Virginia, Phoenix, Dallas, Atlanta, Chicago, Frankfurt, Singapore) by a small set of hyperscaler and AI-lab buyers who signed multi-year framework agreements through 2023 to 2025. The constraint is no longer real estate; it is upstream power and substation capacity, both of which require lead times measured in years. New builds delivering in 2027 and 2028 are already largely accounted for, which means buyers entering the market in 2026 are competing for the next available windows, not for inventory.
Where 1 to 5 MW Capacity Is Still Available (and How to Find It)
Capacity in the 1 to 5 MW range is still findable in 2026, but the inventory does not sit on a public website or a provider's marketing page. It lives in direct conversations between providers and trusted partners about which suite is uncommitted in which hall, which build phase is still open for assignment, and which existing customer is unlikely to take their expansion option. This is the central reason a wholesale AI buyer benefits from a sourcing partner with direct provider relationships and live inventory visibility.
The second-tier markets where 1 to 5 MW capacity is most often available in 2026 include Reno, Columbus, Kansas City, Houston, and Salt Lake City in the US, with similar patterns in EMEA (Madrid, Milan, Warsaw) and APAC (Osaka, Mumbai, Jakarta). These markets often combine available power, viable network connectivity, and providers actively seeking AI anchors at workable rates.
Substation, Transmission, and Grid Interconnection as the Upstream Constraint
Substation capacity, transmission interconnection, and utility load study timelines have become the primary upstream constraint on wholesale AI power capacity, not square footage or capital. A 20 MW campus needs a 20 MW grid interconnect, which depending on the utility and the market can require 18 to 48 months from application to energization (Goldman Sachs, 2025). The implication: a provider advertising a 50 MW master site plan may have 10 MW deliverable in 2026, another 15 MW in 2027 subject to substation expansion, and the balance in 2028 or beyond. Buyers should require the provider's interconnection schedule, not their master site plan, before committing.
Power Density: What Your AI Workload Demands From a Wholesale Facility
Wholesale AI power density is determined by what the workload is doing, with the GPU hardware sitting underneath that as the largest single driver of rack-level kW. A production AI inference deployment serving an end-user product has very different rack-level density and geographic constraints than an AI training cluster running multi-trillion-parameter pre-training, and a wholesale facility committing to either has to design for the specific workload profile rather than a generic "AI ready" number. Buyers who define the workload mix first, then translate that into hardware and density requirements, end up with a facility that fits.
How Rack-Level GPU Density Aggregates Into Hall and Campus Power
Rack power for an AI workload is driven primarily by the GPU SKU and quantity, with major 2026 configurations sitting at very different densities: NVIDIA L40S inference racks at 30 to 40 kW, H100 and H200 racks at 40 to 120 kW, AMD MI300X and MI325X at 60 to 100 kW, NVIDIA B200 single-GPU racks at 60 to 150 kW, and rack-scale Blackwell (GB200 NVL72 and successors) at 130 to 600+ kW. At wholesale scale these aggregate fast. A 5 MW hall packed with B200 servers at 120 kW per rack supports roughly 40 racks; the same 5 MW hall built for L40S inference supports 125+. The hall design follows the rack density, not the other way around.
Mixing AI Training, AI Inference, and LLM Workloads in a Single Wholesale Footprint
Many wholesale AI buyers run mixed workloads inside a single campus, combining training clusters, production LLM and AI inference services, generative AI applications, and supporting infrastructure (storage systems, networking, data pipeline), each with a different rack density, cooling profile, and uptime requirement. A design that accommodates the spread (a liquid-cooled hall for training and high-density inference, an air-cooled hall for storage and lower-density inference, a shared meet-me room for network and cloud on-ramps) is more flexible across a 5 to 10 year term than a single-purpose build.
Forward-Planning for the Next GPU Refresh Inside Your Term
A wholesale AI contract written in 2026 typically runs into 2029 to 2031, which means the buyer is contracting for facility capability that has to host today's GPU SKU and the next two refresh generations. A facility delivering 120 kW per rack today but lacking the chilled water capacity, structural floor load, or substation headroom for 300+ kW racks in 2027 will force a costly mid-term move. Buyers should require the provider to disclose the upgrade path: what density can the hall reach without renovation, and what would a mid-term expansion require.
Cooling Architectures at Wholesale AI Scale
Cooling at wholesale scale is a building-level design problem rather than a rack-level retrofit, and AI data center design in 2026 evaluates three architectures: centralized chiller plants serving district-cooled halls, distributed CDU farms feeding direct-to-chip targeted cooling, and the water and WUE profile that supports either at multi-megawatt scale. The right choice depends on which workload mix the campus is committing to and what the local water and climate constraints permit.
Centralized Chiller Plants and District Cooling
Centralized chiller plants serve multiple halls from a single mechanical plant, providing economies of scale on chilled-water generation and redundancy that distributed CRAC and CRAH designs cannot match at wholesale scale. The design suits mixed-workload campuses where some halls run training at 100+ kW per rack while others run inference at lower density. The trade-off is that the plant has to be sized for worst-case heat load plus growth, which raises capex but reduces marginal cooling cost as halls fill.
CDU Farms and Direct-to-Chip Liquid Cooling at MW Scale
Coolant distribution unit (CDU) farms supply direct-to-chip liquid cooling at the scale modern AI hardware requires, with individual CDUs typically rated at 150 to 200 kW each (sized for a single GB200 NVL72 or equivalent rack) and farms of 20 to 80+ CDUs serving a wholesale hall (Sunbird DCIM,2025). The architecture lets wholesale operators upgrade individual halls to higher-density GPU configurations without rebuilding the central mechanical infrastructure.
Water Availability and WUE as Site Selection Criteria
Water availability and Water Usage Effectiveness (WUE) have become primary site selection criteria for wholesale AI buyers, both because liquid-cooled facilities can consume substantial water under evaporative designs and because corporate sustainability reporting now requires water disclosure. Phoenix and parts of Texas are driving provider decisions toward closed-loop or hybrid designs that minimize evaporative loss. Buyers committing for 5+ years should understand the design WUE and the underlying water source.
Power Procurement, Markets, and Geographic Realities
The geography of wholesale AI capacity in 2026 splits into three layers: primary metros where capacity is largely booked but still strategically valuable for inference proximity, stranded-power and second-tier markets where 1 to 5 MW remains findable and cost-effective, and emerging AI hubs (the Nordics, the Gulf, parts of Asia) where new wholesale capacity is being built at speed. The market a buyer picks should follow the workload, not the other way around.
Primary Wholesale AI Markets
Primary wholesale AI markets in 2026 (Northern Virginia, Phoenix, Dallas, Atlanta, Chicago, Frankfurt, London, Singapore) combine deep carrier connectivity, hyperscaler-adjacent ecosystems, and proximity to end-user populations that matter for inference workloads. They also carry the longest queues for new power, the smallest near-term inventory, and the highest pricing. For training that does not require user proximity, primary markets rarely justify the premium; for production inference, they usually do.
Stranded Power and Second-Tier Markets Where 1 to 5 MW Is Still Findable
Second-tier and stranded-power markets in the US (Reno, Columbus, Kansas City, Houston, the Texas Panhandle, North Dakota and Salt Lake City ) and internationally (Madrid, Milan, Warsaw, Osaka, Mumbai are the most reliable source of 1 to 5 MW wholesale AI capacity in 2026, because they combine available power, lower land cost, and providers actively building inventory aimed at AI buyers priced out of primary markets. The trade-off is reduced latency to major end-user populations, acceptable for training but rarely for production inference.
PPAs, Behind-the-Meter Generation, and Sustainability Reporting
Power procurement for wholesale AI has shifted from a utility-as-default model to a portfolio approach including direct PPAs with renewable generators, behind-the-meter generation (natural gas, fuel cell, and emerging nuclear), and sustainability disclosures that increasingly require hourly carbon attribution rather than annual REC accounting. Buyers with public net zero commitments should confirm the facility's PPA coverage percentage, whether the PPA matches load hourly or annually, and whether the provider supports Scope 2 attribution at the granularity the buyer's stakeholders expect.
Deployment Models for Wholesale AI Colocation
Wholesale AI buyers choose between three deployment models with very different commercial structures, capex profiles, and lead times: build-to-suit (BTS) for maximum design control on the longest timeline, powered shell for faster time-to-power with buyer-funded fit-out, and turnkey wholesale for shortest lead time at a pricing premium. The model that fits depends on how much control the buyer needs, how much capex they can absorb, and how compressed the GPU deployment timeline is.
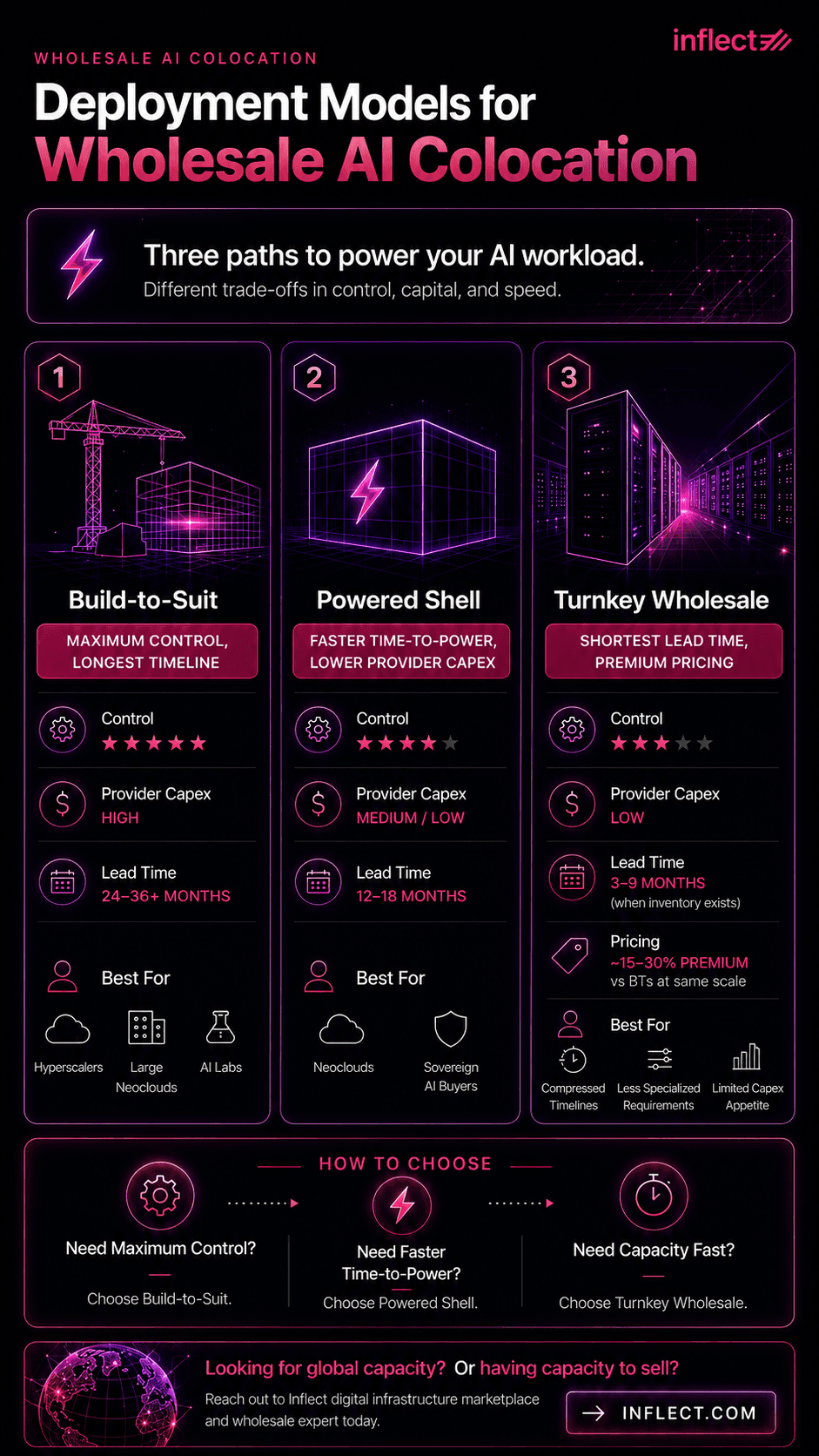
Build-to-Suit: Maximum Control, Longest Timeline
Build-to-suit (BTS) is a custom facility designed and built by the provider to the buyer's specifications, financed by the provider's capex, and leased back on a 10 to 15 year term. It delivers maximum control over electrical, mechanical, and rack-level design, but the timeline from signed BTS agreement to live capacity is typically 24 to 36 months, sometimes longer if substation interconnection is on the critical path. BTS fits hyperscalers, large neoclouds, and AI labs building multi-hundred-megawatt campuses with a known long-term workload.
Powered Shell: Faster Time-to-Power, Lower Provider Capex
Powered shell agreements deliver a building envelope with utility power and basic mechanical infrastructure, leaving the data hall fit-out, racks, cooling, and inside-the-fence electrical to the buyer. The model shortens the timeline (12 to 18 months to ready-for-fit-out) and shifts capex from provider to buyer, which suits buyers with strong balance sheets and clear design preferences. Powered shell is increasingly the dominant model for neoclouds and sovereign AI buyers who want fit-out control without the full BTS commitment.
Turnkey Wholesale: Shortest Lead Time, Premium Pricing
Turnkey wholesale delivers a fully built data hall ready to take racks on day one, with the shortest practical lead time (3 to 9 months when inventory exists). The provider absorbs the design and capex risk, reflected in pricing premiums of roughly 15 to 30% relative to BTS at the same scale. Turnkey fits buyers with compressed GPU timelines, less specialized requirements, or limited capex appetite, and it is where most of the available 1 to 5 MW inventory in second-tier markets actually lives.
Commercial Terms: Down Payments, 3 to 5 Year Minimums, and What's Negotiable
Commercial terms for wholesale AI colocation hardened materially through 2024 and 2025 in response to capacity scarcity, with providers now commonly requiring meaningful upfront commitments, pushing 3 to 5 year minimum terms, and including escalator and pass-through provisions that materially shift risk to the buyer. Knowing what is negotiable, what is not, and what concessions buyers can extract in a market of scarcity is the difference between a defensible contract and one that constrains the buyer for the next five years.
Why Providers Are Asking for Larger Upfront Commitments
Providers across the wholesale AI market are asking for upfront commitments in the form of signing payments, security deposits scaled to 3 to 6 months of base rent, prepayment of the first year, or capacity reservation fees that may or may not credit against future rent. The shift reflects three pressures: rising capex per megawatt (especially for liquid-cooled builds), longer interconnection lead times that demand earlier financial certainty, and the supply-demand imbalance that lets providers ask for terms buyers would have rejected in 2022.
Term Length, Capacity Escalators, and Power Cost Pass-Throughs
Term lengths in 2026 have settled at 3 years on the short end (rare, usually turnkey inventory in second-tier markets) and 5 to 10+ years as standard. Capacity escalators (annual rent increases) sit between 2.5% and 4%, sometimes tied to CPI with a floor and a cap. Power cost pass-throughs are now near-universal, meaning the buyer takes power price risk for the contract duration, which some buyers offset by signing parallel PPAs. Network cross-connect, remote hands, and metered services may carry their own escalators that should be read carefully before signature.
What's Actually Negotiable (and What Isn't)
Negotiable items in 2026 wholesale AI deals include the upfront commitment structure (size, refundability, credit against future rent), term length and renewal options, escalator percentage and CPI mechanics, expansion rights and right-of-first-refusal on adjacent capacity, the deployment model split, and the exit and termination terms. Items that are typically non-negotiable include the deliverable kW per rack and cooling architecture (set by facility design), the substation capacity (set by utility), and the timeline to live power (set by the interconnection queue). Buyers benefit from advisors who know which providers will negotiate which items in the current quarter, because the answer changes more often than annual market reports capture.
When Wholesale Colocation Is the Right Choice
Wholesale colocation is the right architecture for four buyer scenarios where workload scale, cost economics, or strategic control break the retail and cloud models: AI training labs standing up multi-thousand-GPU clusters, neoclouds and GPU-as-a-Service providers scaling to multi-region footprints, hyperscalers adding AI-specific capacity outside their owned footprint, and large enterprises building in-house AI training or production inference at multi-megawatt scale.
AI Training Labs Standing Up Multi-Thousand-GPU Clusters
AI training labs running 5,000+ GPU clusters and other AI accelerators need contiguous, low-latency, single-tenant footprints with the network topology to support InfiniBand or Spectrum-X fabrics across thousands of devices, which retail colocation cannot deliver and cloud service providers cannot deliver at sustained pricing. Wholesale BTS or powered shell in a cheap-power market is the dominant pattern for new training infrastructure.
Neoclouds and GPU-as-a-Service Providers Scaling to Multi-Region
Neoclouds (CoreWeave, Crusoe, Lambda, Nscale, and others) need wholesale capacity in multiple markets simultaneously, with consistent design, consistent commercial structure, and the ability to add capacity in 12 to 18 month windows as GPU shipments arrive. Powered shell and turnkey wholesale across primary and second-tier markets typically fits better than BTS.
Hyperscalers Adding AI-Specific Capacity Outside Their Owned Footprint
Hyperscalers (cloud providers including AWS, Azure, GCP, Oracle, and Meta) are increasingly leasing wholesale colocation to supplement their owned hyperscale facilities for AI deployments in markets where their owned footprint is power-constrained or capacity is years away. The wholesale buy fills the bridge between today's GPU shipments and the hyperscaler's own next-build delivery, often at 50 to 200 MW per deal.
Large Enterprises Building In-House AI Training or Production Inference at Scale
Large enterprises (financial institutions, automakers, defense and aerospace, biotech, big retail) building in-house AI applications for production inference or AI training at multi-megawatt scale now look to wholesale colocation as the alternative to on-premises infrastructure, particularly where capex appetite is limited, time-to-power matters, and the workload is stable enough to justify a 5 year term. The enterprise wholesale segment is the fastest-growing share of new wholesale demand in 2026.
How Inflect Helps You Find Capacity and Negotiate Better Terms
Inflect is the digital infrastructure marketplace and advisory team built for buyers who need to find both retail and wholesale capacity that is not publicly indexed and negotiate terms that providers have hardened across the market, with global coverage across 6,000+ data centers in 100+ countries and free expert advisory at no charge. The platform combines two capabilities wholesale AI buyers cannot easily build in-house: live inventory visibility through direct provider relationships, and advisory expertise that helps structure and negotiate the commercial deal.
On the find side, Inflect surfaces wholesale capacity that providers do not publish: what is uncommitted in which hall, what AI-ready data center inventory is coming online in 2026, 2027, and 2028 subject to interconnection, and what could be built to suit on what timeline in which markets. Visibility extends across primary metros (Northern Virginia, Phoenix, Dallas, Frankfurt, Singapore, Tokyo) and the second-tier markets where 1 to 5 MW is most often findable (Reno, Columbus, Kansas City, Houston, Madrid, Milan, Mumbai), in any market globally where a buyer needs wholesale AI capacity.
On the negotiate side, Inflect's expert advisors, supported by the AI agent Winston, help buyers structure the deal across the dimensions that drive multi-year value: upfront commitment size and structure, term length and renewal options, escalator mechanics, capacity expansion rights, power cost pass-through allocation, and exit terms. Because the advisory team works across hundreds of active deals at any moment, they know which providers are flexible on which items this quarter, which is information no buyer can develop from a single sourcing exercise. Wholesale AI procurement is a market of asymmetric information, and a partner with live market visibility levels the field.
Source Capacity Globally, Negotiate Terms That Hold for Five Years
Wholesale AI colocation in 2026 rewards buyers who treat the decision as three problems in sequence: find the megawatts, design for the workload, and negotiate the terms. The four steps that consistently produce a defensible contract:
Define the workload and capacity envelope: training, inference, or mixed; MW required at signing and at year 3; density assumption; geography
Source candidate capacity across primary and second-tier markets, including inventory not publicly indexed
Match deployment model (BTS, powered shell, or turnkey) to capex appetite and timeline
Negotiate the commercial deal across upfront commitment, term, escalators, and expansion rights using current market intelligence
Search wholesale colocation on Inflect to surface available 1 to 5 MW capacity globally, get forward visibility into 2026 to 2028 inventory and build-to-suit options, and work with the advisory team to negotiate the structure that fits your AI buildout.
About the Author

Chanyu Kuo
Director of Marketing at Inflect
Chanyu is a creative and data-driven marketing leader with over 10 years of experience, especially in the tech and cloud industry, helping businesses establish strong digital presence, drive growth, and stand out from the competition. Chanyu holds an MS in Marketing from the University of Strathclyde and specializes in effective content marketing, lead generation, and strategic digital growth in the digital infrastructure space.
Contact:
Email:
