10 mins
AI Inference Colocation: Power, Cooling, and Network Requirements for GPU-Ready Data Centers
AI inference colocation in 2026 is a power-first problem: rack densities have raced past what most enterprise colocation contracts were ever sized to deliver. The challenge is no longer cost or carrier mix; it is finding the shrinking slice of facilities that can actually host modern GPU hardware close to where your end users live.

The trend driving this is well documented but uncomfortable: GPU rack power has climbed from roughly 25 kW to 130+ kW in two years and is projected to exceed 600 kW per rack by 2027, at a moment when the global supply of facilities engineered for those densities is small, concentrated, and largely spoken for (Goldman Sachs, 2025). AI Inference, unlike training, has to live close to end users, which rules out the cheap-power markets where training capacity gets built.
The decision in 2026 starts with the GPU configuration on the purchase order and works backward to a facility, not the other way around. This guide walks through how that ordering plays out in practice: how GPU choice drives power, cooling, and network requirements, what to ask providers before signing, and the four buyer scenarios where colocation is the right answer.
Why GPU Type And Amount Determine Every Other Colocation Requirement
The GPU type sets the floor for power per rack, the floor for cooling architecture, and the floor for network fabric, in that order, and a colocation contract written without that information first is a contract written for the wrong facility. Total rack power equals GPU TDP (Thermal Design Power) times GPU count plus CPU, memory, storage, and network overhead. Cooling architecture is determined by total rack power. Network fabric is determined by inference workload geography and the bandwidth profile of the model serving stack. Each link is a physical constraint, not a marketing preference.
This matters because traditional enterprise colocation procurement was a bottoms-up exercise: how much rack space, how much power, what carrier mix. AI inference inverts the process. The SKU on your purchase order determines kilowatts per rack, and kilowatts per rack determine which 5% of the global colocation footprint can host you.
GPU Configurations and Their Rack-Level Power Demands in 2026
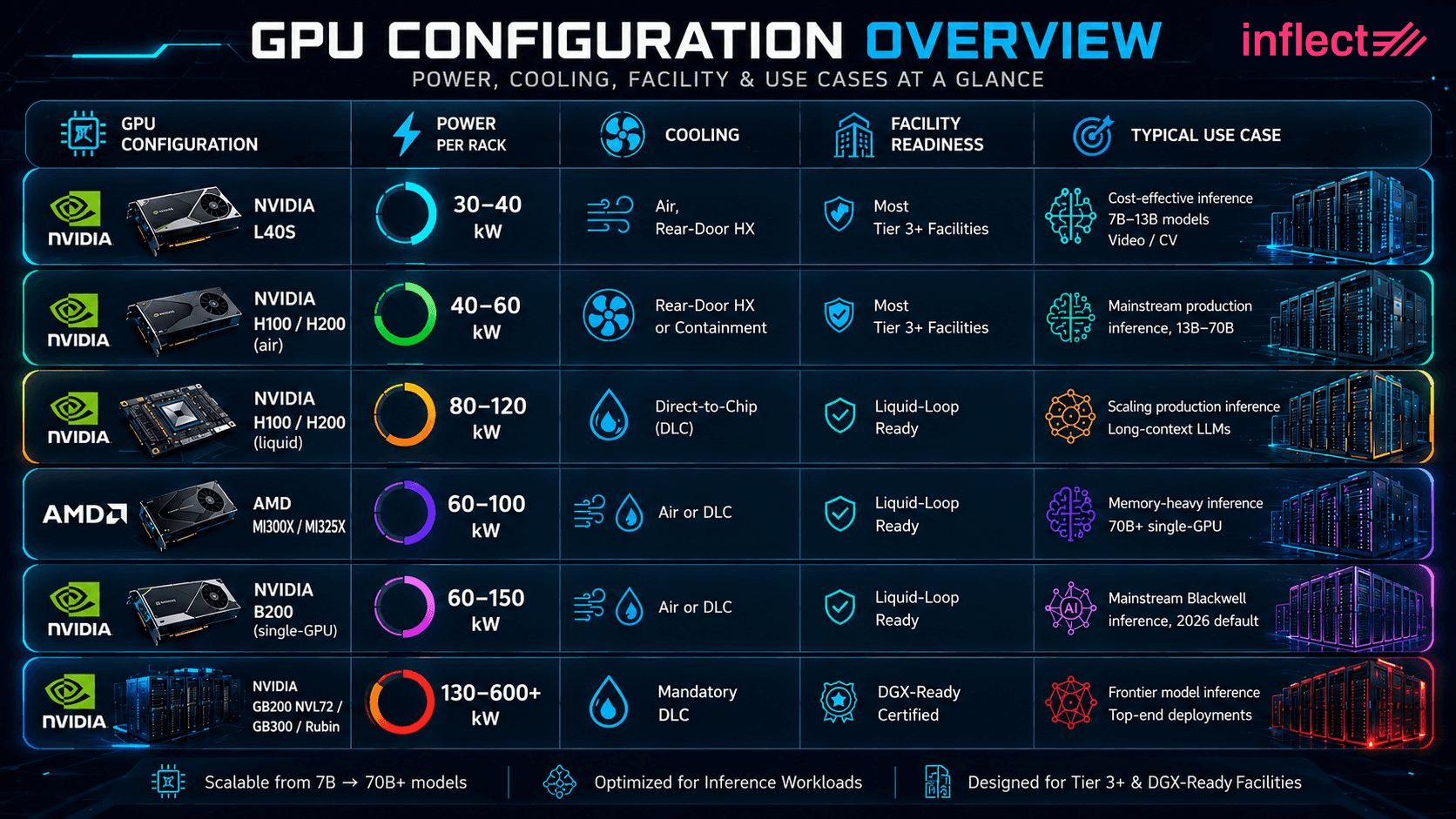
Five GPU configurations dominate AI inference colocation purchases in 2026, each with a distinct power profile, cooling requirement, and facility-readiness implication: NVIDIA L40S inference servers (30 to 40 kW per rack, air cooled), NVIDIA H100 and H200 servers (40 to 120 kW per rack, air or liquid), AMD Instinct MI300X and MI325X servers (60 to 100 kW per rack), NVIDIA B200 single-GPU Blackwell servers (60 to 150 kW per rack), and the rack-scale NVIDIA GB200 NVL72 with the GB300 and Rubin systems that follow it (130 to 600+ kW per rack, mandatory liquid). The configuration you pick determines which providers can host you.
GPU Configuration | Power per Rack | Cooling | Facility Readiness | Typical Use Case |
|---|---|---|---|---|
NVIDIA L40S | 30 to 40 kW | Air, rear-door HX | Most tier 3+ facilities | Cost-effective inference, 7B–13B models, video / CV |
NVIDIA H100 / H200 (air) | 40 to 60 kW | Rear-door HX or containment | Most tier 3+ facilities | Mainstream production inference, 13B–70B |
NVIDIA H100 / H200 (liquid) | 80 to 120 kW | Direct-to-chip | Liquid-loop ready | Scaling production inference, long-context LLMs |
AMD MI300X / MI325X | 60 to 100 kW | Air or DLC | Liquid-loop ready | Memory-heavy inference, 70B+ single-GPU |
NVIDIA B200 (single-GPU) | 60 to 150 kW | Air or DLC | Liquid-loop ready | Mainstream Blackwell inference, 2026 default |
NVIDIA GB200 NVL72 / GB300 / Rubin | 130 to 600+ kW | Mandatory DLC | DGX-Ready certified | Frontier model inference, top-end deployments |
NVIDIA L40S Inference Servers (30 to 40 kW per Rack, Air Cooled)
The NVIDIA L40S has become the cost-leader pick for AI inference, with a 350W TDP per GPU and 1,466 FP8 TFLOPS that make it competitive for 7B to 13B parameter model serving at a fraction of H100 cost (Source: NVIDIA L40S datasheet, nvidia.com; Yotta Labs, Best GPUs for LLM Inference in 2026. yottalabs.ai). An 8-GPU L40S server consumes 4 to 5 kW, so a rack of 6 to 8 servers lands between 30 and 40 kW, comfortably inside the operating envelope of most tier 3 and tier 4 colocation facilities with rear-door heat exchangers.
For inference buyers running cost-sensitive endpoints or video and computer vision workloads, the L40S is often the right starting point before stepping up to Hopper-class hardware.
NVIDIA H100 and H200 Servers (40 to 120 kW per Rack, Air or Liquid)
NVIDIA H100 and H200 servers are the workhorse of 2026 enterprise AI inference, with the H100 SXM drawing 700W per GPU and the H200 keeping the same envelope while adding 141GB of HBM3e for memory-heavy workloads (NVIDIA, 2026). 8-GPU servers consume 6.5 to 8 kW each, putting air-cooled racks at 40 to 60 kW with rear-door heat exchangers or hot/cold aisle containment, and liquid-cooled racks at 80 to 120 kW with direct-to-chip cold plates.
The H100 is the most widely deployed Hopper GPU in production worldwide. The H200 is preferred for long-context LLMs (128K to 1M tokens), multimodal systems, and agentic AI workflows that benefit from the larger memory pool.
AMD Instinct MI300X and MI325X Servers (60 to 100 kW per Rack)
AMD Instinct MI300X and MI325X have become a meaningful alternative for AI inference workloads where memory capacity is the bottleneck, with the MI300X offering 192GB of HBM3 and the MI325X offering 256GB of HBM3E, both running at roughly 750W per GPU (amd.com). The larger memory pools enable single-GPU inference for models up to 70B parameters without sharding, which simplifies the serving stack and reduces inter-GPU bandwidth pressure on the rack network. 8-GPU AMD servers run 8 to 10 kW each, with rack densities at 60 to 100 kW depending on cooling architecture.
Hyperscaler adoption is significant, and PCIe-form-factor variants now fit in standard 4U server chassis suitable for most colocation facilities.
NVIDIA B200 Single-GPU Blackwell Servers (60 to 150 kW per Rack)
NVIDIA B200 single-GPU servers, distinct from the rack-scale GB200 NVL72, are the emerging mainstream for 2026 Blackwell inference deployments, with B200 GPUs drawing roughly 1,000W each and 8-GPU servers consuming 10 to 12 kW. Air-cooled deployments land at 60 to 80 kW per rack; liquid-cooled deployments push to 100 to 150 kW. B200 supply was constrained through late 2025 but availability improved in early 2026 as Blackwell production scaled (ThunderCompute, 2026).
For most enterprise AI inference deployments below the frontier-model tier, B200 servers, not the rack-scale GB200 NVL72, are the practical Blackwell entry point.
NVIDIA GB200 NVL72 and Successors (130 to 600+ kW per Rack, Mandatory Liquid)
The NVIDIA GB200 NVL72 is a 72-GPU rack-scale system designed for frontier-model inference and training workloads, drawing 120 to 132 kW per rack and requiring direct-to-chip liquid cooling, a CDU sized at 150 to 200 kW per rack, and inlet coolant temperatures below 45°C (Sunbird, 2025). The follow-on GB300 NVL72 ships at roughly 163 kW per rack, the 2026 Vera Rubin NVL144 is projected to require 300+ kW, and the 2027 Rubin Ultra NVL576 is forecast to exceed 600 kW (Goldman Sachs Insights, 2025).
As of late 2025, only 47 facilities globally met NVIDIA's published DGX-Ready standards for 120 kW racks, the gating constraint for any buyer planning rack-scale Blackwell at scale. For most enterprise inference workloads, this rack-scale tier is the wrong fit; B200 single-GPU servers or Hopper-class H100 and H200 hardware will be more appropriate.
Top Requirements for AI Inferencing Colocation
Power Provisioning Implications for AI Inferencing Colocation
Once the GPU SKU is fixed, power provisioning becomes a downstream specification exercise covering whip sizing, redundancy topology, branch circuits, PUE expectations, and sustainability reporting. A buyer who arrives without those specs receives a quote built around the provider's defaults, not the deployment's needs.
Recommend Reading: How to Buy AI-Ready Datacenter Colocation: The 2026 Digital Infrastructure Procurement Guide
Whip Sizing, Topology, and Branch Circuits
High-density GPU racks at 100 kW and above require 415V or 480V three-phase power distribution, A/B redundant feeds (2N is now standard for production inference), and branch circuit sizing that reflects steady-state load plus 20% headroom for peak transients. Standard 120V or 208V single-phase distribution does not scale to GPU densities, and retrofitting a cabinet from 208V to 415V is a non-trivial electrical project that can take weeks (Netrality, 2025). The contractual point: specify deliverable kW per rack, not design capability. A facility advertising "100 kW capable" with distribution sized for 30 kW per cabinet is not deliverable for your deployment.
PUE (Power Usage Effectiveness) Targets and What Liquid Cooling Does to Them
PUE for liquid-cooled GPU facilities should land in the 1.10 to 1.20 range, materially better than the 1.40 to 1.60 typical of air-cooled enterprise colocation, because direct-to-chip cooling removes heat at the source rather than conditioning entire room volumes, lowering total facility power consumption per token served. NVIDIA has reported that the Blackwell platform's liquid cooling can deliver up to 300x improvement in water efficiency over traditional air cooling, which translates directly into lower Scope 2 emissions per token served (NVIDIA, 2025).
Sustainability and Scope 2 Reporting
Enterprise procurement teams now routinely require renewable PPA coverage, hourly carbon intensity reporting, and water use disclosure as contract terms. The relevant questions are: what percentage of the facility's electricity is contracted under renewable PPAs, what is the documented Water Usage Effectiveness (WUE), and can the provider deliver hourly carbon attribution for inference workloads.
Cooling Architectures That Actually Work at GPU Density Colocation
Three cooling architectures are in active deployment for GPU colocation in 2026, each with a defined density ceiling: rear-door heat exchangers (effective up to ~70 kW per rack), direct-to-chip liquid cooling (the 2026 default for 80 to 200+ kW per rack), and immersion cooling (a niche but expanding option for specific workload profiles). The GPU configuration determines which architecture the facility must support, not the other way around.
Where Air Cooling Stops Working
Air cooling, including hot/cold aisle containment and standard CRAC/CRAH rooms, becomes thermally insufficient between 30 and 50 kW per rack, after which the room itself acts as a bottleneck. Water has a heat transfer coefficient roughly 3,500 times greater than air, which is why every GPU configuration above the H100 and H200 air-cooled tier has moved to liquid (Tom's Hardware, 2025). A facility advertising "high density" without a liquid cooling capability is high density only by yesterday's standards.
Direct-to-Chip Liquid Cooling: The 2026 Default
Direct-to-chip (DLC) liquid cooling is the dominant 2026 architecture for GPU colocation, accounting for roughly 65% of the deployed liquid cooling market, because it removes heat at the source via cold plates affixed directly to the GPU and CPU dies, which is both thermally efficient and compatible with NVIDIA's reference designs for Blackwell and Rubin systems (KAD, 2026). Buyer-side specifications to validate: coolant flow rate per module (typically 2 to 3 L/min), maximum inlet coolant temperature (45°C is the published GB200 NVL72 spec), CDU capacity per rack (150 to 200 kW), and whether the facility runs single-phase or two-phase cold plates.
Rear-Door Heat Exchangers and Immersion Cooling
Rear-door heat exchangers handle up to 70 kW per rack and fit inside a standard cabinet footprint, making them well-suited for facilities transitioning from air-cooled to fully liquid-cooled designs. Immersion cooling supports densities above 200 kW per rack and reduces water usage but requires bespoke server hardware and remains a smaller share of new deployments. For inference buyers, the practical choice is usually between DLC and rear-door heat exchangers.
Network Requirements for Production AI Inference
AI inference workloads create three distinct network requirements that each have to be specified separately in a colocation contract: high-bandwidth east-west fabric inside the colocation footprint (now 400G and 800G for multi-rack inference clusters), low-latency north-south access to end users (which determines geographic placement), and direct cloud on-ramp connectivity (for hybrid inference architectures). Skipping any of the three creates production performance issues that cannot be fixed after move-in.
Looking for Data Center Network Connectivity? Search now.
400G and 800G East-West Fabrics for Multi-Rack Inference
Multi-rack inference clusters running large language models, transformer models, or distributed model serving require 400G or 800G east-west fabric between racks, typically built on NVIDIA Quantum InfiniBand or Spectrum-X Ethernet, because token throughput scales with inter-GPU bandwidth as soon as the model is sharded across more than one server. A colocation facility that supports 100G top-of-rack networking but does not provide cross-rack 400G fabric is the wrong facility for production inference at scale.
The buyer-side question to ask: what is the rated cross-connect bandwidth between racks in the same suite, and how is it cabled.
Latency to End Users and the Case for Edge Inference
Inference workloads, unlike training, are latency sensitive and benefit from facilities located within roughly 10 to 30 milliseconds of end users, which is why production inference is distributed across multiple metros rather than concentrated in cheap-power markets where training is consolidated. Real-time AI applications, including chat, voice, virtual assistants, natural language processing, speech recognition, and agentic AI, typically target sub-200ms end-to-end response, of which network round-trip is a significant fraction. Hyperscaler-adjacent hubs (Ashburn, Dallas, Phoenix, Bay Area, Frankfurt, Singapore, Tokyo) command premium pricing, while second-tier metros (Kansas City, Philadelphia, Houston, Reno) are emerging as cost-effective alternatives where network paths to end users remain within tolerance.
Cloud On-Ramps and Hybrid Inference Architectures
Most production inference deployments are hybrid, retaining a public cloud footprint for bursting and elastic training while running steady-state inference in colocation. Direct cloud on-ramps to AWS Direct Connect, Azure ExpressRoute, and Google Cloud Interconnect are non-negotiable line items, and carrier-neutral facilities with deep cross-connect inventory (Megaport, Equinix Fabric, Console Connect, and the major NSPs) carry more long-term value than single-carrier sites.
Questions to Ask AI Inference Colocation Providers Before You Sign
Before signing a AI Inference colocation contract, ask the provider seven specific questions and require numerical or evidentiary answers rather than marketing language: deliverable kW per rack today, cooling architecture and density ceiling, contracted cross-rack network bandwidth, available cloud on-ramps with measured latency, compliance certifications covering the facility, GPU-trained remote hands and SLA tiers, and the contractual path for power upgrades.
The seven questions, with the answers buyers should expect:
Power per rack, deliverable today. A number in kW with a contract amendment available, not "designed for" language. For a GB200 NVL72, the floor is 132 kW per rack, A/B feed, 2N, 415V or 480V three-phase.
Cooling architecture and density ceiling. Air, rear-door HX, DLC, or immersion, with a published supported density. For Blackwell, "DLC with CDU sized 150 to 200 kW per rack" is the right answer.
Cross-rack network bandwidth. 100G, 400G, or 800G with cabling specifics. For multi-rack inference, 400G or 800G InfiniBand or Spectrum-X is the floor.
Cloud on-ramps. Named carriers and round-trip latency to AWS, Azure, and GCP, with cross-connect pricing.
Compliance certifications. SOC 2 Type II, ISO 27001, HIPAA (healthcare), PCI DSS (fintech), plus NIST AI RMF alignment and EU AI Act readiness for regulated AI systems.
Remote hands and SLA. GPU-trained hands 24/7, MTTR under 4 hours, uptime SLA at 99.999% or better with credit structure.
Power upgrade path. Contractual right to expand kW per rack within the term, cost per additional kW, lead time for capacity provisioning.
If a provider answers any of the seven with marketing language rather than numbers, the contract is being written against your interests.
When AI Inference Colocation Makes Sense
AI inference colocation is the right architecture for four buyer scenarios where workload characteristics, cost economics, or compliance break the public GPU cloud model: AI startups scaling production inference beyond cloud quota constraints, SaaS companies adding AI features to an existing product, enterprises repatriating AI workloads from public cloud, and ML platform teams that need denser and more predictable infrastructure than cloud GPU instances provide.
AI Startups Scaling Production Inference Beyond GPU Cloud Quotas
AI-native startups running production inference at meaningful token volume hit two ceilings simultaneously: GPU cloud cost economics deteriorate at sustained utilization (the cloud premium pays for elasticity that production inference does not need), and quota constraints on the latest GPU SKUs limit scaling. Colocation with owned or leased Blackwell hardware addresses both, typically delivering 40–70% lower run‑rate cost above ~70% utilization (McKinsey, 2025).
SaaS Companies Adding AI Features to an Existing Product
SaaS companies embedding generative AI features (copilots, summarization, recommendations) face the same per-token economics problem at lower volume, plus a margin pressure problem: AI feature revenue rarely maps cleanly to inference cost, and on cloud that cost grows linearly with usage. A colocation footprint sized for steady-state inference, with public cloud retained for bursting, restores margin predictability.
Enterprises Repatriating AI Workloads from Public Cloud
Enterprises with substantial early cloud investment in AI inference are increasingly repatriating workloads to colocation when token volume exceeds approximately 500 million per month, when data residency rules apply, or when a stable workload profile makes cloud's elasticity premium pure overhead. Repatriation also restores control over GPU generation choice, which has become a procurement priority as Blackwell and Rubin ship.
ML Platform Teams Needing Denser, More Predictable Infrastructure
Internal machine learning (ML) platform teams supporting multi-team inference workloads need GPU density and topology guarantees that public cloud GPU instances do not provide: specific NVLink and InfiniBand topology, specific GPU generations co-located in the same rack, and predictable performance for AI model latency benchmarks. Colocation delivers those guarantees in a way the cloud abstraction explicitly does not.
How Inflect Helps You Source GPU-Ready Colocation
Inflect is the digital infrastructure marketplace built for buyers who need to find, compare, and contract GPU-ready colocation in the markets and densities their AI inference workload requires, with instant pricing across 6,000+ data centers in 100+ countries and free expert advisory at no charge. The platform solves the central problem this guide describes: the right facility is determined by the GPU SKU, the geography, and the network topology, and most procurement processes lose weeks chasing facilities that cannot deliver on one or more of those.
On Inflect, buyers search by deliverable kW per rack, by cooling architecture (air, rear-door HX, direct-to-chip liquid, immersion), by certification (DGX-Ready, SOC 2, ISO 27001, HIPAA), by cloud on-ramp coverage, and by metro market, then receive instant pricing without a sales call. Expert advisors, supported by the AI agent Winston, help translate a GPU configuration into a facility specification and shortlist in any market globally. Because the GPU-ready footprint is constrained and bid windows are short, surfacing every viable facility for a specific configuration at instant pricing is materially faster than serial RFQs.
Build the Specification, Then Find the Facility
AI inference colocation in 2026 rewards buyers who lead with the GPU SKU and let power, cooling, and network specifications flow from it. The four steps that consistently produce the right contract:
Confirm the GPU configuration first: H100 vs H200, air vs liquid, GB200 vs GB300, and whether the facility needs to be Rubin-ready in 2027
Translate that configuration into a deliverable kW per rack, a cooling architecture, and an east-west network bandwidth requirement
Match the requirement against actual facility capabilities in the metros that meet your latency and cloud on-ramp needs
Use instant pricing to compare options side by side rather than issuing serial RFQs
Search GPU-ready colocation on Inflect to start with instant pricing on facilities that match your GPU configuration, density, cooling, and network requirements in any market globally.
-> Have AI Inference Colocation Expert Source The Right Colo For Your Business
About the Author

Chanyu Kuo
Director of Marketing at Inflect
Chanyu is a creative and data-driven marketing leader with over 10 years of experience, especially in the tech and cloud industry, helping businesses establish strong digital presence, drive growth, and stand out from the competition. Chanyu holds an MS in Marketing from the University of Strathclyde and specializes in effective content marketing, lead generation, and strategic digital growth in the digital infrastructure space.
Contact:
Email:
