11 mins
GPU Cluster Networking: InfiniBand vs. RoCE for Large-Scale AI Training
Sixty hours into a multi-node LLM pre-training run, the GPUs are not the problem. Compute utilization is high. The job scheduler is healthy. But throughput has degraded below projections, and the culprit is gradient synchronization: thousands of AllReduce operations are stalling, waiting on a network fabric that cannot keep pace with the parallel collective communication demands of a 1,024-GPU cluster. The training run will finish late. The compute budget will overrun.

This is not a rare failure mode. As distributed, scale-out AI training workloads expand to hundreds and thousands of GPUs, the network interconnect becomes the dominant variable in training efficiency. The GPU itself is no longer the bottleneck. The fabric is.
At stake is more than a hardware selection. A fabric decision made at cluster design time is difficult and expensive to reverse. It affects training throughput, operational risk, time-to-production, and total infrastructure cost over a multi-year deployment lifecycle. For organizations running or planning large-scale AI training workloads, this is a material business decision, not a networking preference.
This post provides a technical and economic decision framework for choosing between InfiniBand and RoCEv2: how each fabric works, where each performs well, how total cost of ownership actually compares across cluster scale tiers, and what to verify before committing to an infrastructure provider.
Why GPU Cluster Networking Determines AI Training Timelines and Infrastructure Cost
GPU cluster networking determines AI training speed and cost because distributed training requires continuous, low-latency synchronization between GPUs, making the network fabric the rate-limiting factor in AI data center deployments as cluster size grows. The specific mechanism is collective communication: frameworks like NCCL coordinate gradient exchange across every GPU in a cluster using operations such as AllReduce and AllGather, which require all participating nodes to complete each synchronization step before any can proceed. Switch topology, whether fat-tree or dragonfly, determines how many hops separate any two GPUs and directly shapes how quickly these operations complete at scale. A fat-tree topology provides full bisection bandwidth and predictable latency; a dragonfly topology reduces cabling cost but introduces hop-count variability that can amplify tail latency under contention.
Why Collective Communication Amplifies Small Network Inefficiencies Into Measurable Budget and Schedule Overruns
Collective communication amplifies network inefficiencies because AllReduce in a distributed training job requires every GPU in the cluster to both send and receive gradient data before the next compute step begins, so the slowest synchronization in any iteration determines the pace of all of them. To make this concrete: assume a 30-day LLM pre-training run across 1,024 H100-class GPUs, priced at $3 per GPU per hour (illustrative, based on prevailing bare metal rates for H100-class hardware, mid-2025; actual pricing varies by provider and contract structure), with full-time cluster utilization. At those parameters the run costs approximately $2.2 million in compute. A 5% network-induced efficiency loss, well within the range caused by a misconfigured or undersized fabric, produces roughly 36,864 wasted GPU-hours. At $3 per GPU per hour, that is approximately $110,000 in direct compute waste, plus roughly 1.5 additional training days added to the schedule. These figures are illustrative and depend on actual utilization rates, job scheduling, and pricing. The structural point stands: even modest network inefficiency at scale produces budget and schedule overruns that substantially exceed the cost difference between interconnect options.
How InfiniBand Delivers Consistent, Low-Tail-Latency Performance Under Contention at Frontier Scale
InfiniBand delivers consistent GPU-to-GPU communication through a purpose-built fabric that combines native RDMA, hardware-level congestion management, and adaptive routing in a single integrated stack, without requiring the lossless Ethernet configuration that RoCEv2 depends on. NVIDIA’s current Quantum-2 InfiniBand platform, the seventh generation of NVIDIA’s InfiniBand architecture, supports up to 400Gb/s per port for NDR and 200Gb/s for HDR, and it is designed for the high-concurrency traffic patterns common in large-scale AI training. (Source: NVIDIA, 2025)
Why Tail Latency, Native RDMA, and Graceful Incast Behavior Define InfiniBand's Advantage at Scale
InfiniBand's operational advantage in large-scale AI training comes from three properties that matter more than peak throughput: tail latency under contention, native RDMA without prerequisite fabric configuration, and graceful behavior during incast events. Tail latency is the metric that determines AllReduce completion time across thousands of GPUs, because the entire cluster waits for the last node to finish each synchronization round. InfiniBand's hardware-enforced congestion management and adaptive routing keep tail latency stable during synchronized burst traffic, which is precisely what collective communication generates at scale.
Incast, the condition in which many senders simultaneously target a small number of receivers, is one of the most destructive network events for collective communication. InfiniBand handles incast through credit-based flow control at the hardware level, preventing buffer overflow and packet loss without requiring explicit queue management configuration from the operator. Native RDMA removes the CPU from the data path entirely, which eliminates a latency source and reduces jitter. Together these properties mean InfiniBand cluster performance under real training workload conditions closely tracks its specifications, and deviations from expected throughput are typically traceable to topology or compute issues rather than fabric behavior. That reliability and predictability are worth more to teams running long, high-value training jobs than the headline bandwidth figure alone conveys.
Why Hyperscalers Bet on Ethernet Economics, and What RoCEv2 Demands From Your Team
Hyperscalers invest in Ethernet-based GPU fabrics because the cost-per-port economics of high-speed Ethernet switches are significantly lower than InfiniBand at the scale of tens of thousands of GPUs, and because Ethernet's open ecosystem allows procurement flexibility that a proprietary InfiniBand stack does not. At hyperscaler scale, a fabric built on 400 GbE or 800 GbE switches can deliver competitive throughput for many AI training workloads at a fraction of the switch and cabling cost of an equivalent InfiniBand deployment. The tradeoff is that Ethernet, as a link layer protocol, is inherently a lossy transport, and RoCEv2 requires that lossiness to be engineered out through careful fabric configuration. How well an organization manages that configuration is the primary variable determining whether a RoCE deployment performs at InfiniBand-class levels or struggles under production load. That is an organizational variable as much as a technical one: teams without dedicated network engineers experienced in QoS at this level carry meaningfully higher deployment risk regardless of which hardware they procure.
Why RoCEv2 Fabric Configuration Is the Variable That Separates a High-Performance Deployment From One That Struggles Under Production Load
RoCEv2 typically achieves RDMA performance over Ethernet by using a lossless or near-lossless fabric, commonly implemented with three mechanisms: Priority Flow Control, or PFC, to pause specific traffic classes and prevent buffer overflow, Explicit Congestion Notification, or ECN, to mark congestion before packet loss occurs, and DCQCN, or Data Center Quantized Congestion Notification, to reduce sender rates in response to congestion signals. (Source: Juniper Networks, 2026) Each of these mechanisms must be correctly configured across the fabric and tuned for the workload’s traffic pattern. Misconfigured PFC can create head-of-line blocking, overly weak ECN marking can let microbursts fill switch buffers, and poorly tuned DCQCN can reduce throughput under high fan-out traffic. RoCEv2 carries RDMA over UDP/IP and commonly uses UDP destination port 4791, which is why operators aim to keep the fabric lossless or near-lossless rather than depend on packet loss recovery at higher layers. (Source: Juniper Networks, 2026)
This is not a problem solved once during initial deployment. RoCEv2 fabrics require ongoing operational expertise to maintain under changing workload conditions, new job types, and cluster expansion. Organizations with strong in-house networking teams and existing investment in high-speed Ethernet infrastructure are well positioned to manage this. Organizations without dedicated network engineers who understand QoS configuration at this level face substantially higher risk of performance degradation, extended validation timelines, and training run failures before the fabric stabilizes.
InfiniBand vs. RoCE Total Cost of Ownership Across Cluster Scale Tiers
InfiniBand and RoCEv2 carry different TCO profiles across three cluster scale tiers: small clusters of up to 128 GPUs, mid-scale clusters from 128 to 1,024 GPUs, and large-scale clusters above 1,000 GPUs. RoCE's cost advantage is clearest at small scale, genuinely ambiguous at mid-scale once operational overhead is included, and highly dependent on organizational networking maturity at large scale. Hardware-only cost models that exclude configuration time, validation cycles, and failure recovery systematically understate RoCE's real cost at mid-to-large scale. The correct comparison is always total cost over the deployment lifecycle, not switch and cable pricing alone.
Why Time-to-Stable-Cluster and Failure Recovery Cost Belong in Your TCO Model
Time-to-stable-cluster and failure recovery cost belong in any honest TCO comparison because they represent real budget and schedule exposure that hardware-only models miss. InfiniBand clusters typically reach stable, validated production performance faster after initial deployment because the fabric's congestion management and flow control operate without operator configuration. A RoCEv2 cluster at mid-to-large scale may require weeks of tuning and validation before collective communication performance stabilizes across all workload types. During that period, cluster utilization is lower, bandwidth utilization is uneven across the fabric, training jobs may produce unreliable throughput, and engineering time is consumed by fabric debugging rather than model development.
When a RoCEv2 misconfiguration causes a training run to stall or degrade mid-job, the recovery cost includes the GPU-hours lost before detection, the engineering time to diagnose and resolve the configuration fault, and the delay to the training schedule. In a large cluster running high-value pre-training jobs, a single such event can exceed the capital cost difference between the two fabric options. This does not make RoCEv2 the wrong choice. It means the TCO case for RoCEv2 must be constructed with these costs explicitly included, not assumed away.
How NVIDIA's Vertical Integration and the Ultra Ethernet Consortium Shape Long-Term Procurement Economics
NVIDIA’s 2020 acquisition of Mellanox for $6.9 billion created a vertically integrated InfiniBand stack in which the dominant GPU vendor also controls a leading high-performance interconnect. Organizations that standardize on NVIDIA GPUs plus InfiniBand networking can increase dependency on a single vendor across compute and fabric, which may affect pricing leverage, upgrade flexibility, and contingency options if supply or pricing conditions change over a multi-year cluster lifecycle. (Source: NVIDIA, 2020)
The Ultra Ethernet Consortium, formed in 2023 with founding members including AMD, Arista, Broadcom, Cisco, HPE, Intel, and Meta, is developing an open specification for RDMA-capable Ethernet fabrics aimed at AI and HPC workloads, with the goal of approaching InfiniBand-class performance on open Ethernet hardware. Its specification is still maturing, and production-validated deployments at scale remain limited as of mid-2025. Organizations making fabric decisions today with a three-to-five year lifecycle in view should track UEC progress as a potential procurement option that could shift the long-term cost calculus. (Source: Ultra Ethernet Consortium, 2023)
A Decision Framework for Choosing GPU Cluster Interconnect
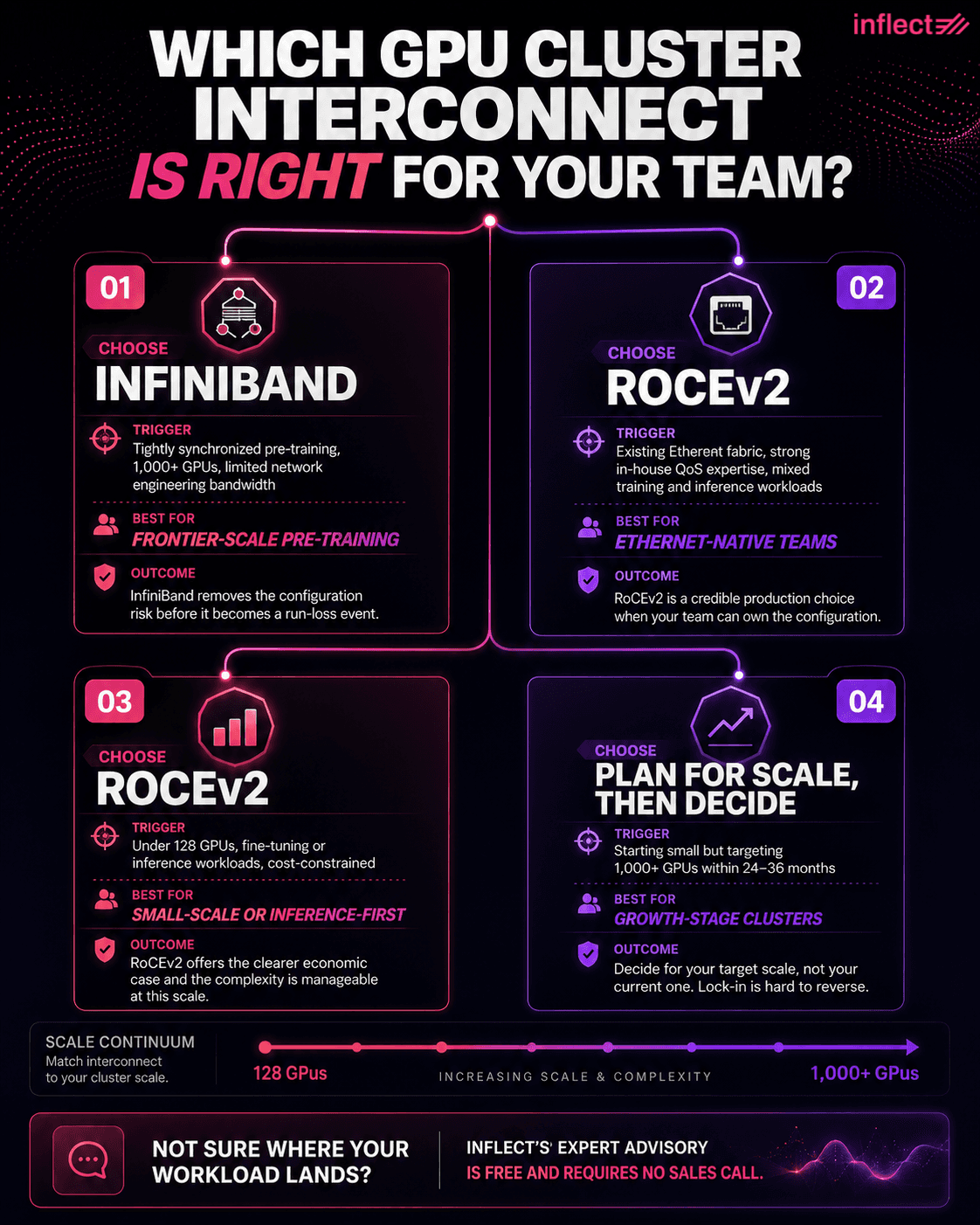
The choice between InfiniBand and RoCEv2 depends on four axes evaluated together: workload latency sensitivity and synchronization pattern, organizational networking maturity, scale trajectory and budget constraints, and time-to-production requirements. No single axis is determinative; the right choice is the intersection of all four, weighted for the specific conditions of the organization making it.
If the workload is tightly synchronized pre-training at 1,000 or more GPUs, training runs are long-lived and high-value, and the team does not have dedicated network engineers with QoS expertise, InfiniBand removes the configuration risk that would otherwise become a run-loss liability. If the organization already operates large-scale Ethernet infrastructure with strong in-house QoS and congestion management expertise, cost sensitivity is a primary driver, and the cluster will serve a mix of training and inference workloads with varying latency requirements, RoCEv2 is a credible and well-precedented production choice. If the cluster is under 128 GPUs, workloads are primarily fine-tuning or inference rather than large pre-training jobs, and capital cost is constrained, RoCEv2 offers the clearer economic case and the configuration complexity is more manageable at that scale. If the cluster will scale from a smaller initial deployment to 1,000 or more GPUs over a 24-to-36-month period, the fabric architecture decision made at initial deployment carries significant lock-in implications, and scale trajectory should weight the decision toward whichever option remains viable and cost-effective at the target scale, not the current one.
What to Ask GPU Infrastructure Providers Before You Commit to a Fabric
Before committing to a bare metal or colocation provider for a GPU training cluster, buyers should verify six specific variables about the provider's network fabric: network connectivity architecture (fat-tree or dragonfly topology, and the oversubscription ratio at each tier), which interconnect generation is deployed (InfiniBand NDR or HDR, or RoCEv2 and at what line rate), whether the fabric has been validated for multi-node distributed training workloads, what NCCL AllReduce benchmark results the provider can share at the cluster sizes relevant to the buyer's workloads, how RoCEv2 configuration and ongoing tuning are handled and by whom, and what the resolution process and timeline is for fabric-level performance issues after deployment begins. Providers who cannot answer these questions with specifics are unlikely to have the operational infrastructure to support a serious AI training deployment at scale.
What This Means for Your Next Cluster Decision
The 60-hour training run that opened this post does not have a single correct answer, but it has a preventable outcome. With InfiniBand, the fabric's native congestion management and tail latency stability would have kept collective communication throughput close to its theoretical ceiling under that synchronized workload. With RoCEv2, the same result is achievable, but only with a correctly configured fabric operated by a team with the expertise to maintain it under production conditions and catch configuration drift before it becomes a run-loss event. The choice between them is not a technical preference. It is a risk-adjusted infrastructure decision that should account for cluster scale, scalability trajectory, workload characteristics, organizational networking maturity, and the full cost of deployment over time, not just the hardware line items. Buyers who evaluate all four axes before committing to a fabric are the ones whose training budgets and timelines reflect what was planned.
Sourcing GPU Cluster Infrastructure on Inflect
Inflect is a digital infrastructure marketplace where buyers can search, compare, and receive instant pricing from bare metal and colocation providers across more than 6,000 facilities in over 100 countries, without a sales call. For teams sourcing GPU cluster infrastructure, the platform enables direct comparison of provider offerings, including network fabric specifications, allowing buyers to evaluate interconnect options alongside compute, facility, and pricing variables in a single workflow rather than through separate sales conversations with each provider.
Providers available on Inflect with high-performance compute and colocation infrastructure include Equinix, Digital Realty, NTT, and CoreSite, alongside a broader set of bare metal and colocation providers across North America, Europe, and Asia Pacific. Buyers comparing InfiniBand and RoCEv2 environments across providers, verifying fabric topology details, or assessing pricing before committing can use Inflect's platform alongside free expert advisory to structure that evaluation.
Start Your GPU Infrastructure Search
For teams scoping a GPU training cluster and comparing infrastructure options before committing to a fabric or provider:
Get instant pricing from providers
Search bare metal and GPU colocation providers across 6,000+ facilities instantly, with no sales call required
Compare network fabric specifications, topology, and capacity side by side across providers
Access free expert advisory to evaluate InfiniBand vs. RoCEv2 environments against your specific workload and scale requirements
About the Author

Haley Rogers
Content & Social Media Specialist
Haley Rogers is the Content & Social Media Specialist at Inflect, bringing over two years of experience in social media, marketing, and content strategy — including time at a fast-paced tech company before joining the Inflect team. She specializes in translating complex digital infrastructure topics into clear, engaging content, with a particular focus on blog writing and brand storytelling across channels.
Contact:
