13 mins
Bare Metal for HPC: How to Choose Infrastructure for Compute-Intensive Jobs
Whether to run HPC workloads on bare metal or cloud is not a technology preference question. It is a performance predictability question, and the answer turns on a single variable that most cloud cost calculators obscure: the crossover point where sustained utilization on dedicated hardware costs less and performs more consistently than a fleet of virtualized instances.

For workloads running at 70% utilization or higher over a sustained period, the economics of bare metal shift decisively. But cost is only half the calculation. For jobs that require InfiniBand networking, RDMA-based collective communication, or specific cluster topologies such as fat-tree or dragonfly, the performance gap between bare metal and cloud is not a matter of optimization. It is architectural. Virtualized network overlays and shared infrastructure introduce latency and jitter that no cloud configuration eliminates.
This post covers the architectural differences that produce that gap, the workload profiles where bare metal delivers consistently superior results, the evaluation criteria and specifications that should anchor any provider shortlist, and the total cost and risk framework buyers need to make a defensible infrastructure decision. The questions in the final section are designed to expose gaps that most providers will not volunteer.
Bare Metal vs. Cloud for HPC: The Architectural Differences That Impact Performance
Bare metal infrastructure and cloud HPC differ across three architectural dimensions that directly determine workload performance: compute isolation, network interconnect design, and memory and storage access patterns.
Why Virtualization Overhead Matters at HPC Scale
Hypervisor-based cloud instances can add CPU overhead, memory virtualization penalties, and I/O latency that compound at HPC scale. A 2026 HPC performance study found that virtual machine environments still trail containers on CPU, memory, I/O throughput, and execution latency across multiple workloads (Source: International Journal of Scientific Research and Innovation, 2026). Beyond raw overhead, shared cloud infrastructure introduces noisy neighbor effects: co-tenants executing unrelated workloads can cause CPU steal, memory bandwidth contention, and performance variability that results in inconsistent job completion times. For deterministic workloads such as molecular dynamics simulations or financial risk model calibrations, that unpredictability is operationally unacceptable. Bare metal eliminates the virtualization layer entirely, giving jobs direct and exclusive access to the physical resources of the server: CPU cores, memory channels, and PCIe lanes.
Dedicated Interconnects and Network Topology: InfiniBand, RDMA, and the Latency Gap Cloud Cannot Close
The interconnect layer is where the performance gap between bare metal HPC and cloud HPC becomes most quantifiable. Microsoft’s 2026 Charmed HPC benchmark documentation reports 200 Gb/s HDR InfiniBand bandwidth and 1.59 microseconds of InfiniBand latency on a two-node test, underscoring how tightly tuned interconnects shape MPI performance (Source: Ubuntu Documentation, 2026). Standard cloud Ethernet, even with RDMA over Converged Ethernet (RoCE), typically runs 2 to 5 microseconds for latency at the NIC level, and cloud overlay networks for virtualized environments can add multiples of that baseline. The HPC interconnect latency comparison between a purpose-built InfiniBand fabric and a shared cloud network is not marginal: it is a 10x to 50x difference in the worst case. Remote direct memory access (RDMA) bypasses the operating system kernel entirely, allowing GPUs and CPUs on different nodes to access each other's memory directly, which is essential for distributed AI training executing AllReduce collective communication and for message passing interface (MPI)-based simulation codes exchanging large intermediate datasets between nodes at every iteration.
Network topology compounds the effect. A fat-tree topology with a 1:1 oversubscription ratio ensures every node has full bisection bandwidth to every other node regardless of cluster size. Dragonfly topologies reduce network diameter for very large clusters, making them practical for top-tier supercomputing deployments. Most cloud providers apply oversubscription ratios of 4:1 or higher on shared network fabric, which means bandwidth per node degrades as the cluster scales. Rail-optimized topologies, which dedicate separate network planes to storage traffic and GPU collective communication, deliver measurably better throughput than shared fabric designs and are only achievable on dedicated bare metal infrastructure.
Memory Bandwidth and Storage Configurations for Data-Intensive Jobs
High-performance computing workloads, especially genomics pipelines and large-scale simulation codes, are often limited by memory bandwidth rather than raw compute throughput. Bare metal deployments let teams control memory channel count, DIMM speed, and NUMA layout, which directly affect sustained node bandwidth. For GPU-accelerated workloads, NVIDIA H100 SXM5 systems using NVLink can provide up to 900 GB/s of GPU-to-GPU bandwidth (Source: Spheron, 2026). Storage access follows the same pattern: parallel file systems such as Lustre and GPFS deliver the aggregate I/O bandwidth that genomics and CFD workloads require at scale, and deploying those file systems requires direct hardware control that cloud abstraction layers do not provide.
HPC Use Cases Where Bare Metal Consistently Outperforms Cloud
Bare metal HPC consistently outperforms cloud HPC across five workload categories where sustained GPU utilization, low-latency interconnects, deterministic scheduling, or high I/O throughput are operational requirements: AI and machine learning model training, computational fluid dynamics, genomics and life sciences sequencing, financial risk modeling, and high-performance rendering.
AI and Machine Learning Training at Sustained GPU Utilization
Distributed AI training on GPU clusters is the fastest-growing driver of bare metal HPC demand, because model FLOP utilization (MFU) is directly sensitive to interconnect latency and bandwidth consistency. A distributed training job running AllReduce operations across 64 or more GPUs is constrained by the slowest communication step in each iteration. InfiniBand-connected bare metal clusters achieve MFU values of 45% to 55% on large transformer models; equivalent cloud configurations with virtualized networking consistently underperform that range due to latency variability and bandwidth oversubscription. For organizations running sustained AI training infrastructure, the combination of dedicated interconnects and fixed cost structures makes bare metal the operationally and economically superior choice over multi-month training campaigns.
Computational Fluid Dynamics and Structural Simulation
CFD and structural simulation codes such as OpenFOAM, Ansys Fluent, and LS-DYNA are tightly coupled MPI workloads that exchange large data volumes between nodes at every time step. These codes scale efficiently on bare metal clusters with InfiniBand and fat-tree topologies, and they perform poorly on cloud infrastructure where network latency and bandwidth oversubscription disrupt the synchronization pattern. Engineering and manufacturing teams running aerodynamic simulations, finite element analysis, turbine design analysis, crash simulation, advanced simulations for climate modeling, or weather forecasting workloads gain both performance and scheduling determinism from dedicated bare metal HPC infrastructure.
Genomics, Proteomics, and Life Sciences Sequencing Pipelines
Genomics pipelines combine high-throughput compute with extreme I/O demands: a single whole-genome sequencing run can generate hundreds of gigabytes of raw data that must move rapidly between compute nodes and storage. Bare metal configurations allow direct specification of NVMe storage, parallel file system architecture, and network topology to match the specific I/O profile of the pipeline. Cloud equivalents introduce storage abstraction layers and network bottlenecks that extend job runtimes and increase per-sample cost for high-volume sequencing operations. For scientific research organizations running at clinical or population-scale sequencing volumes, the I/O performance gap is the primary reason to operate on dedicated hardware.
Financial Risk Modeling and Quantitative Analytics
Risk analytics, quantitative research, and big data analytics workloads require deterministic execution times to meet end-of-day batch windows. A Monte Carlo simulation that completes in 45 minutes on bare metal should not take 55 minutes due to noisy neighbor effects on a high-volatility trading day. Bare metal HPC infrastructure gives quant teams the performance consistency and scheduling control they need, along with the ability to specify security configurations that meet financial regulatory requirements without relying on multi-tenant cloud isolation controls.
High-Performance Rendering and Media Processing
Visual effects studios and media organizations running large rendering jobs benefit from bare metal's predictable node availability and consistent throughput. Cloud spot or preemptible instances offer cost savings for burst rendering, but production pipelines with firm delivery deadlines require guaranteed compute access. Bare metal clusters provide the reservation guarantees that production rendering workflows require, along with the GPU memory capacity and interconnect bandwidth that large scene rendering demands.
How to Evaluate Bare Metal Providers for HPC: The Criteria That Matter
Evaluating bare metal providers for HPC requires assessment across five dimensions: compute and power density, network topology and interconnect options, storage architecture, cluster orchestration and scheduling support, and provisioning timelines.
CPU, GPU, Memory, and Power Density: What HPC Workloads Actually Require
Modern HPC workloads, especially AI training infrastructure built around H100- or H200-class GPUs, require power densities that exclude many standard colocation facilities. NVIDIA’s DGX H100/H200 system documentation shows a six-power-supply design and system-level electrical requirements that place the platform well into high-density data center territory (Source: NVIDIA, 2026). A rack of four DGX H100 nodes requires 100 kW or more of power delivery and direct liquid cooling infrastructure. For CPU-bound HPC systems, Intel Xeon processors and AMD EPYC at high core counts deliver the computing power required for memory-bandwidth-intensive jobs; confirm the CPU generation and memory channel configuration as part of any hardware evaluation. When evaluating bare metal HPC providers for GPU-accelerated workloads, confirm the maximum kW per rack available, the cooling model (air versus direct liquid cooling), and the provider's operational experience with high-density GPU deployments. Providers who have not supported H100 or B200-class workloads at scale will have neither the power infrastructure nor the operational procedures to support them reliably.
Network Topology and Interconnect Options at Scale
HPC infrastructure providers should be evaluated on whether they support InfiniBand HDR or NDR, RoCE v2, or both, and on whether their cluster topology delivers non-blocking or low-oversubscription interconnect at the scale you require. Ask for the specific switch generation, port count per leaf and spine, and oversubscription ratio at your target cluster size. Providers who cannot answer these questions precisely have not built production HPC environments. For scalable HPC infrastructure running distributed AI training workloads, rail-optimized topologies that dedicate separate network planes to storage traffic and GPU collective communication deliver optimal performance across all HPC nodes, with measurably better throughput than shared fabric designs.
Storage Architecture: NVMe, Parallel File Systems, and Scratch Storage
HPC storage NVMe and parallel file system evaluation should cover three distinct tiers: high-performance NVMe scratch storage for active job data, parallel file system access (Lustre or IBM Spectrum Scale/GPFS) for large datasets shared across compute nodes, and archive storage for completed runs. Confirm that the provider supports or manages a parallel file system deployment, what the aggregate read and write bandwidth is at your expected job scale, and whether scratch storage is physically local to compute nodes or attached over the network fabric. Locally attached NVMe delivers sub-millisecond latency and represents the baseline for high performance storage in HPC environments; network-attached storage over a shared fabric introduces contention that compounds under multi-job loads.
Job Schedulers and Cluster Orchestration: Slurm, Kubernetes, and Hybrid Models
Slurm is one of the dominant workload managers in HPC cluster orchestration and is used across much of the TOP500 supercomputer list, including many of the fastest systems (Sources: SC24, 2024; TOP500, 2026). If your workload management depends on Slurm-based job queues, resource reservations, or fairshare scheduling, confirm that the provider supports Slurm and at what operational depth. For organizations converging AI training with traditional HPC, Kubernetes-based orchestration is increasingly relevant, particularly for containerized distributed computing workloads that need to share cluster resources with Slurm-managed jobs. Some providers offer hybrid schedulers that manage both simultaneously. Evaluate based on your existing software stack, toolchain, and the operational overhead your team can absorb.
Provisioning Lead Times and Their Impact on Time-to-Science
Bare metal provisioning timelines range from same-day for pre-configured standard configurations to four to eight weeks for custom hardware deployments at scale. HPC provisioning lead times have direct consequences for research projects, product launch timelines, and model training schedules. When evaluating providers, ask for the specific lead time for your target configuration, the committed SLA for provisioning, whether rapid provisioning is available for standard configurations, and whether capacity is available on demand or requires advance reservation. Providers who have not deployed your target GPU generation before will carry longer lead times than those with established supply chain relationships for that hardware. In HPC contexts, a six-week provisioning delay is a missed research window, not a scheduling inconvenience.
Bare Metal vs. Cloud for HPC: Total Cost and Risk of Ownership
Bare metal HPC delivers lower total cost of ownership than cloud HPC at sustained utilization levels above approximately 60%, and introduces specific financial and operational risks below that threshold that buyers must model before committing.
When Cloud HPC Is Still the Right Call
Cloud HPC remains the correct choice for three scenarios: workloads with genuinely unpredictable demand that cannot be scheduled in advance, burst capacity requirements that exceed permanent cluster size for short periods, and development and testing environments where jobs run intermittently and do not justify dedicated hardware. The decision to use cloud is correct when utilization would fall consistently below 40%, when the cost of idle hardware exceeds the premium paid for on-demand access, or when the workload does not require InfiniBand interconnects and runs effectively on virtualized Ethernet.
The Sustained Utilization Crossover Point
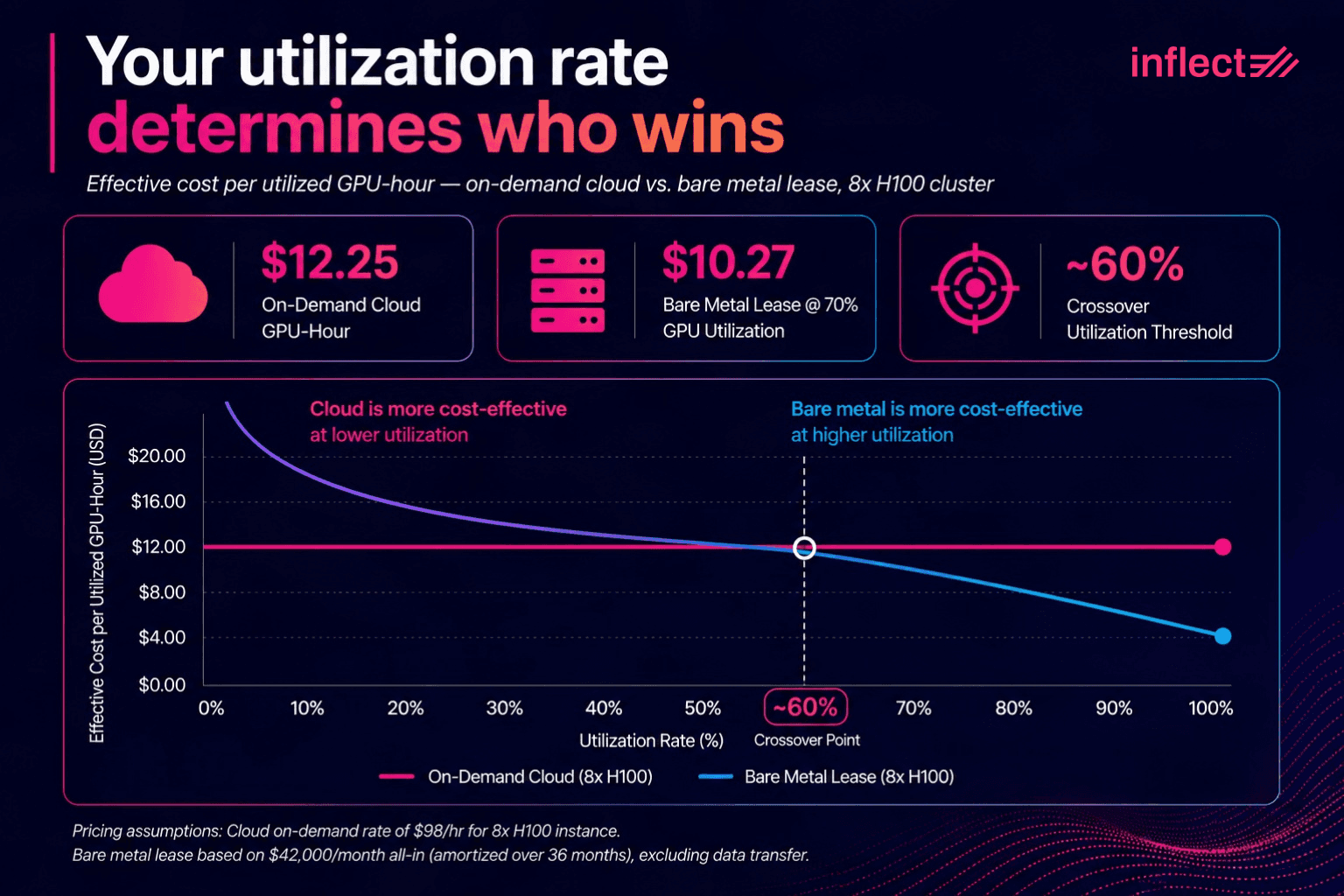
The economic crossover between cloud and bare metal HPC is a function of utilization rate, contract duration, and the specific configuration. The following comparison uses illustrative market rates for an 8-node H100 cluster running at 70% utilization over 12 months; actual rates vary by provider, region, and contract structure (labeled as modeled estimates).
Cloud on-demand (8x H100 SXM5, equivalent instance): approximately $98 per hour. At 70% utilization over 8,760 annual hours, total annual spend approaches $600,000. Effective cost per GPU-hour: approximately $12.25.
Bare metal lease (8x H100 SXM5, dedicated server): approximately $42,000 per month all-in at current market rates, inclusive of hardware, managed hosting, and facility costs, amortized over 36 months. Annual cost runs approximately $504,000. Effective cost per GPU-hour: approximately $10.27.
At 70% sustained utilization, bare metal delivers cost efficiency of approximately 16% relative to cloud on-demand rates, before accounting for egress fees. The gap widens significantly at higher utilization rates. (Source: modeled estimates based on publicly listed rates from major cloud and bare metal providers, June 2026.) The crossover threshold shifts lower for longer contract terms and higher-utilization workloads, and shifts higher for configurations with significant idle periods.
Egress and Data Transfer Costs at HPC Data Volumes
Cloud egress pricing can range from about $0.05 to $0.09 per GB beyond free-tier thresholds, depending on provider, region, and transfer path (Source: Google Cloud, 2024). For a genomics team processing 500 TB of sequencing data annually, egress alone adds $25,000 to $45,000 to the cloud total cost of ownership. For AI training organizations moving massive datasets, model checkpoints, and inference outputs between cloud regions or to on-premises storage, data transfer costs are a recurring and often underestimated line item in the GPU cloud vs. bare metal cost comparison. Bare metal HPC infrastructure hosted in a colocation facility replaces cloud egress fees with predictable cross-connect or network transit costs that are structurally lower at HPC data volumes.
Operational and Financial Risks of the Wrong HPC Infrastructure Model
The primary financial risk of bare metal is underutilization: a committed lease on hardware running at 30% utilization is expensive relative to on-demand cloud, and that cost cannot be recovered mid-contract. The primary operational risk of cloud HPC for tightly coupled workloads is the absence of consistent performance: inconsistent job completion times affect batch scheduling, research timelines, and production SLAs in ways that are difficult to diagnose and impossible to contractually remediate. The third risk category, applicable to both models, is procurement lag. Bare metal provisioning delays of four to eight weeks and cloud capacity shortfalls for H100 and B200 hardware in constrained regions have both caused material project delays in recent GPU procurement cycles. Modeling procurement timelines into infrastructure decisions is not optional for teams with hard launch or research delivery dates.
Questions to Ask a Bare Metal Provider Before You Commit
Buyers evaluating bare metal providers for HPC should ask questions across four categories before signing: performance guarantees and dedicated resource SLAs, hardware refresh cycles, cluster expansion capacity, and support response times for production environments.
Performance Guarantees and Dedicated Resource SLAs
Ask for a written SLA that guarantees dedicated access to named hardware resources, documents the provider's uptime commitment for power and network, and specifies remedies for SLA breaches. A provider who cannot commit to 99.99% uptime for power and cooling in a Tier III or Tier IV facility is not appropriate for production HPC workloads. Also confirm that the hardware is not shared with other tenants under any circumstance, including maintenance windows, and that performance commitments extend to the interconnect fabric, not just the compute nodes. For workloads involving sensitive data, request documentation of the physical access controls and logical isolation procedures in place at the facility.
Hardware Refresh Cycles and Performance Decay Over Contract Lifetime
GPU hardware generations turn over on a 12 to 24 month cycle. Signing a 36-month bare metal contract for H100-class hardware means running on a configuration that is two GPU generations behind by contract end, while competing organizations operate on more capable infrastructure. Ask the provider what their hardware refresh policy is, whether they offer mid-contract upgrade options, and what the process and cost is for transitioning to the next GPU generation during the contract term. A provider without clear answers is not operating at production HPC scale, and the performance decay over the contract lifetime will be a real and compounding cost.
Cluster Expansion and Capacity Guarantees
Many bare metal providers can deliver an initial cluster configuration but cannot guarantee contiguous expansion capacity when a team needs to scale from 8 nodes to 32. For growing HPC workloads running on scalable HPC infrastructure, ask the provider to commit in writing to expansion capacity at a specified notice period. Confirm whether reserved expansion capacity carries a hold fee, what the maximum cluster size the provider has delivered in your target region is, and whether expansion nodes will be on the same hardware and interconnect generation as the initial deployment. A cluster that cannot expand within your data center footprint forces a disruptive migration at the worst possible time.
Support Response Times for Production HPC Environments
HPC jobs often run over days or weeks, which means a hardware failure mid-job results in lost computation and potentially days of rerun time. Ask the provider for their committed response time for hardware replacement, whether they maintain on-site spares for the GPU models in your configuration, and what their escalation path is for critical failures affecting production workloads. For production environments, a next-business-day response time is not sufficient. Four-hour hardware replacement SLAs with on-site spares are the operational baseline for serious HPC deployments.
How Inflect Helps HPC Buyers Source Bare Metal Infrastructure
Inflect is a digital infrastructure marketplace where buyers sourcing HPC solutions can search and compare bare metal servers, dedicated servers for HPC workloads, and data center HPC colocation options with instant pricing, without a sales call. The platform covers 6,000+ facilities across 100+ countries, with inventory from providers including Equinix, Digital Realty, NTT, Iron Mountain, QTS, CoreSite, and Flexential, alongside specialized bare metal providers operating at HPC scale.
For organizations evaluating HPC infrastructure providers, Inflect surfaces instant pricing across configurations and regions, enabling direct comparison of bare metal GPU cluster costs against cloud benchmarks. Buyers sourcing high-density GPU compute in specific markets can filter by power density, available GPU generation, and interconnect support rather than waiting for individual provider sales teams to respond to RFPs. The platform's free expert advisory connects HPC buyers with advisors who have direct experience structuring bare metal contracts, modeling utilization crossover points, and evaluating interconnect specifications across provider configurations.
Start comparing bare metal HPC infrastructure on Inflect:
Search GPU cluster and dedicated server configurations with instant pricing
Filter by power density, GPU generation, and interconnect type for HPC-specific requirements
Compare bare metal total cost of ownership against cloud benchmarks before you commit
Access free expert advisory with no sales call and no commitment required
About the Author

Haley Rogers
Content & Social Media Specialist
Haley Rogers is the Content & Social Media Specialist at Inflect, bringing over two years of experience in social media, marketing, and content strategy — including time at a fast-paced tech company before joining the Inflect team. She specializes in translating complex digital infrastructure topics into clear, engaging content, with a particular focus on blog writing and brand storytelling across channels.
Contact:
