12 mins
AI Inference on Bare Metal: Performance, Cost, and Deployment Guide
The cloud bill arrives on a Tuesday morning. Not the training bill, which every team expects to be large. The inference bill. Twelve months into production, with a model serving real users at real volume, the team is paying $4 per GPU-hour around the clock for capacity that never fully idles. The number no longer fits the line item it was originally budgeted under.

This guide is written for infrastructure and ML engineering teams at exactly that moment. It assumes a production inference workload, predictable traffic, and a finance team treating the compute line as a capital planning question. If your traffic is bursty, GPU utilization is low, or the model is still being iterated on, most of what follows does not apply yet. For teams past that threshold, IDC projects worldwide AI spending — including AI software, services, and infrastructure — will reach approximately $632 billion by 2028, with inference workloads expected to represent an increasing share of the associated compute demand (Source: IDC, 2024).
When AI Inference Outgrows Public Cloud
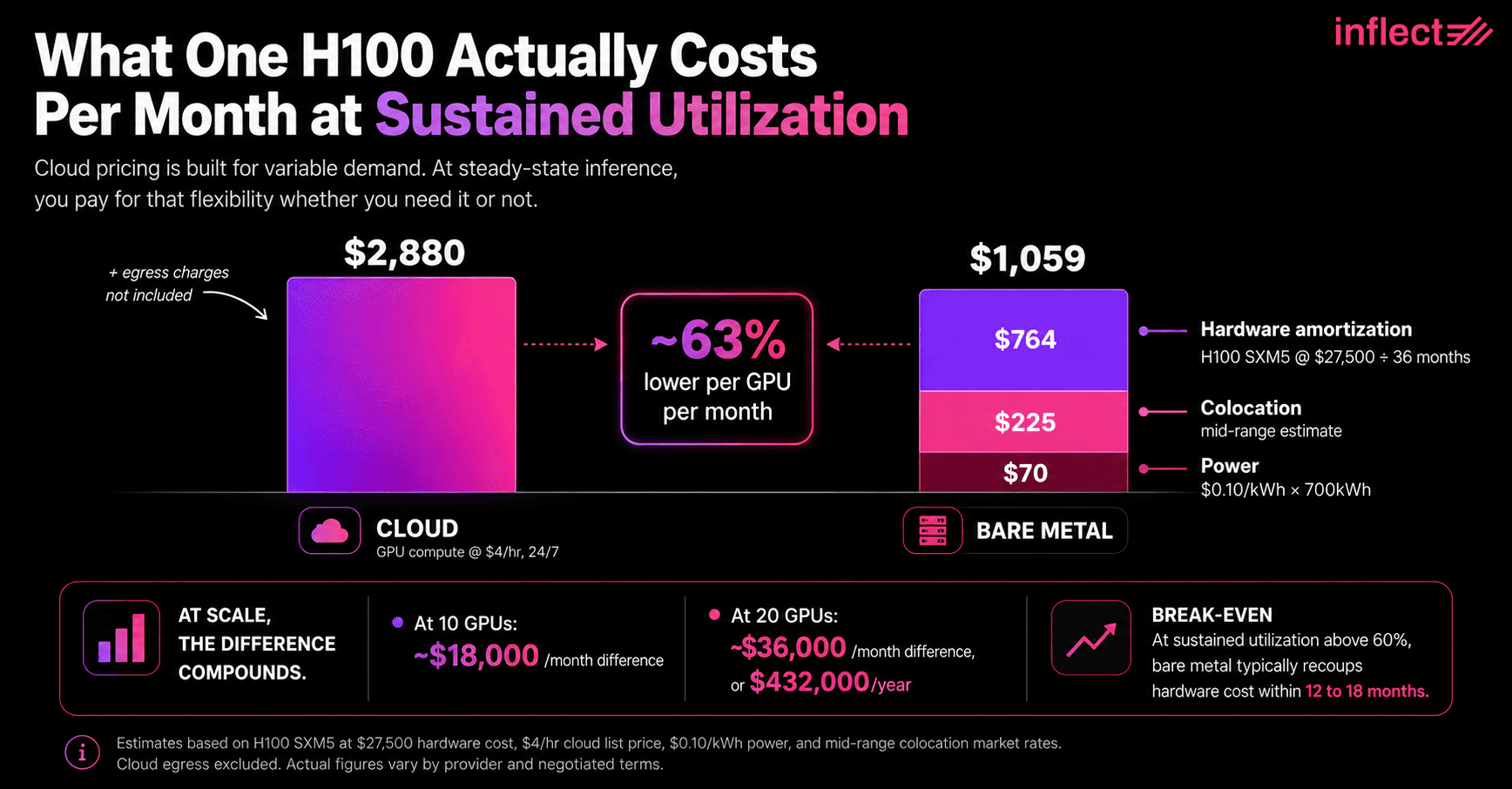
Cloud GPU pricing is designed for variable demand, and at sustained utilization it becomes one of the most expensive ways to run production AI inference. An NVIDIA H100 on major GPU cloud providers typically runs between $3.50 and $4.50 per hour (Source: Lambda Labs, 2025; CoreWeave, 2025), putting a single H100 at roughly $2,880 per month at $4.00/hour, 24/7. By comparison, an H100 SXM5 purchased outright at $25,000 to $30,000, amortized over 36 months, falls to about $700 to $830 per month in hardware cost alone. Add power (assume $0.10/kWh, roughly 700 kWh monthly per GPU) and colocation (on the order of $150 to $300 per GPU-equivalent per month), and the all-in total lands between approximately $1,000 and $1,300 per month. At sustained utilization, bare-metal AI infrastructure runs at roughly 35 to 45 percent of the effective cost of equivalent cloud GPU capacity.
How Cloud Egress Charges Compound Invisibly at Inference Scale
Egress pricing on major hyperscalers typically runs between $0.08 and $0.09 per GB for the first 10TB per month (Source: AWS, 2025). For an inference API returning rich outputs at high concurrency, those charges often accumulate quietly and then surface at invoice time as a material line item. Teams running LLM inference at meaningful token volumes commonly report egress accounting for roughly 10 to 20 percent of total cloud compute cost once traffic stabilizes.
The TCO Break-Even Framework for AI Inference
The AI inference TCO analysis for bare metal vs. cloud depends on three inputs: average GPU utilization across the current cloud deployment, monthly cloud spend on inference compute, and the loaded cost of dedicated hardware including amortization, power, colocation, and operations staffing. At sustained GPU utilization above 60 percent, the cost efficiency of dedicated hardware typically surpasses equivalent cloud capacity within 12 to 18 months on an amortized basis. Teams should model this using actual utilization telemetry, not projections, before committing to hardware.
Latency Ceilings on Shared Infrastructure
Multi-tenant cloud GPU environments introduce P99 latency variance that dedicated bare metal eliminates, because shared infrastructure creates contention at the memory bus, NVLink fabric, and network layer that no amount of instance-level tuning can fully remove. For inference APIs with enterprise SLAs requiring P99 response times under 500 milliseconds, the unpredictability of shared environments becomes a ceiling the team cannot engineer past. Achieving low latency AI inference at that tier requires dedicated hardware free from multi-tenant contention, which is why high performance production deployments disproportionately run on bare metal.
Data Residency and Compliance Constraints
Some inference workloads cannot run on hyperscaler infrastructure because contractual, regulatory, or data classification requirements mandate physical control over the hardware processing the data. Healthcare organizations handling protected health information, financial services firms with data sovereignty requirements or real-time fraud detection workloads subject to strict localization rules, and defense contractors processing controlled unclassified information all face scenarios where shared compute is not a permissible option. For these teams, bare metal in a compliant colocation facility is not primarily a cost decision. It is the only permissible production AI inference architecture.
How to Choose Hardware for AI Inference on Bare Metal
Selecting the right bare metal servers for AI inference requires matching GPU memory capacity, compute throughput, and network interface configuration to three workload parameters: the size of the model being served, the concurrency profile of the inference API, and the latency targets the deployment must reliably meet.
NVIDIA H100, A100, and L40S: Matching GPU to Inference Profile
The three most widely deployed AI accelerators for running deep learning models and LLM inference in production are the NVIDIA H100, A100, and L40S, each suited to a different workload profile. The H100 SXM5 provides 80GB of HBM3 memory and up to 3.35TB/s of memory bandwidth, making it a strong fit for large models above roughly 70 billion parameters and high-concurrency deployments where time-to-first-token is the primary SLA metric (Source: NVIDIA, 2023). The A100 80GB remains cost-effective for mid-size models in the 7 to 70 billion parameter range. The L40S targets inference-centric workloads with its Ada Lovelace architecture and 48GB of GDDR6, offering attractive throughput-per-dollar for models at or below roughly 34 billion parameters (Source: NVIDIA, 2023).
VRAM Requirements and Memory Bandwidth by Model Size
A model's minimum VRAM requirement is its parameter count multiplied by bytes per parameter at the precision being used. A 7B model at FP16 requires approximately 14GB just to load model weights, with additional memory for KV cache during active inference. A 70B model at FP16 requires approximately 140GB, exceeding single-GPU capacity and requiring either quantization or multi-GPU deployment. GPU utilization optimization for AI inference starts here: calculate VRAM headroom for peak KV cache at target concurrency levels, not just static model weight size.
Network Interface Configuration for High-Concurrency Inference APIs
High-concurrency inference APIs require 25GbE or 100GbE network interfaces with SR-IOV enabled to prevent CPU bottlenecks at the network layer during peak traffic. For GPU clusters serving thousands of concurrent requests, bonded 2x25GbE or single 100GbE NICs prevent the network from becoming the throughput ceiling before GPU utilization reaches its practical maximum.
Power Density and Cooling Requirements for GPU-Dense Racks
GPU inference nodes at density require 10 to 30kW per rack, well above the 5 to 8kW average of a standard enterprise data center rack. Facilities supporting AI workloads require high-density air cooling with hot-aisle containment or direct liquid cooling depending on rack density, and the energy efficiency of the facility's power infrastructure directly affects operating costs at GPU scale. Teams selecting colocation for AI workloads should confirm per-rack power availability and cooling method before committing, since retrofitting an underpowered cage after hardware is racked is not a practical option.
Designing and Optimizing a Production Inference Stack
A production AI inference architecture on bare metal consists of a serving framework, an orchestration layer, load balancing and routing, an observability stack, and a security architecture, all configured at design time to meet throughput, latency, and compliance targets rather than adjusted reactively after deployment.
Inference Serving Frameworks: vLLM, TensorRT-LLM, and Triton Compared
The three leading inference serving frameworks for LLM inference infrastructure are vLLM, TensorRT-LLM, and NVIDIA Triton Inference Server, each optimized for a different deployment context. vLLM provides broad model support and an efficient continuous batching engine based on PagedAttention, making it a fast path to production for many teams (Source: Cornell University, 2023). TensorRT-LLM delivers very high throughput on NVIDIA GPUs through kernel fusion and compilation that is aware of quantization, at the cost of a more complex build and optimization process. Triton is best suited for multi-model deployments that need a unified serving layer across different model types and backends.
Built-In Support for Quantization and Batching at the Serving Layer
Modern inference frameworks expose INT8 and FP8 quantization and continuous batching as first-class configuration options at deploy time, so throughput and latency targets are now driven primarily by architecture and deployment choices rather than ad hoc post-deployment tuning. Enabling FP8 quantization on H100 deployments can increase tokens-per-second throughput by roughly 30 to 50 percent compared to BF16 on compatible models, with minimal accuracy degradation reported on most production-grade LLMs (Source: NVIDIA, 2024). Continuous batching reduces average latency under variable concurrency by dynamically grouping in-flight requests, making it a critical scaling strategy for real-time inference APIs with uneven request arrival patterns.
Observability Stack for Inference Performance Monitoring
A production observability stack for bare metal AI model deployment infrastructure should capture four metric categories: GPU utilization and memory pressure per device, P50/P95/P99 request latency at the API layer, token throughput in tokens per second per GPU, and queue depth as a leading indicator of capacity saturation. Prometheus with NVIDIA DCGM exporter covers GPU-level telemetry; OpenTelemetry handles distributed tracing across the serving layer. Alerting thresholds should be set on P99 latency and queue depth rather than GPU utilization alone.
Security Architecture for Inference Endpoints Handling Sensitive Data
Inference endpoints processing regulated or proprietary data require network segmentation at the facility and host level, mutual TLS for all API traffic, and role-based access control on the model serving layer. For workloads subject to HIPAA, SOC 2, or FedRAMP requirements, the colocation facility must carry the relevant certifications and the inference deployment must be isolated from shared tenant networks. These are not configurations to retrofit after a compliance audit.
Colocation vs. On-Premises for Bare Metal AI Inference
The decision between colocation and owned data center space for bare metal AI inference involves a tradeoff between cost savings and operational ownership that every team must evaluate honestly against their staffing model, capital budget, and infrastructure maturity.
The Tradeoff: Cost Savings vs. Operational Ownership
Moving inference to bare metal delivers meaningful AI infrastructure cost reduction, but it transfers hardware lifecycle management, physical troubleshooting, and capacity planning from a cloud provider to your team. A failed GPU in cloud is replaced by the provider within minutes; a failed GPU in a colocation cage requires a hardware support contract, a spare-parts strategy, or remote hands. The staffing cost is a necessary counterweight to the compute savings in any realistic TCO model.
Power and Cooling Infrastructure: Why Most Teams Lease Rather Than Build
Building owned data center space capable of supporting GPU inference at high rack densities requires significant upfront capital investment that is rarely justified below hyperscaler scale, and typical new-build timelines of roughly 18 to 36 months are impractical for teams that need additional capacity within 6 to 12 months (Source: JLL, 2025). Colocation provides access to commissioned power and cooling infrastructure as an operating expense, allowing teams to add GPU capacity on much shorter timelines without funding and managing a full data center build.
Five Criteria for Evaluating Colocation Providers for AI Workloads
Colocation providers capable of supporting AI inference workloads must satisfy five criteria: per-rack power availability of at least 20kW with a path to 30kW or above, liquid cooling or high-density air cooling with hot-aisle containment, carrier-neutral interconnect options, proven GPU deployment experience with referenceable customers, and SLA terms covering power availability and remote hands response time at the hardware layer.
Colocation Contract Terms That Matter for AI Infrastructure
AI infrastructure teams negotiating colocation agreements should secure specific language on three points: a power commitment guaranteeing per-rack kW allocation for the full term, an expansion right at a pre-agreed rate as the GPU cluster grows, and a remote hands SLA with defined response times. Standard enterprise colocation contracts are not written with high-density GPU workloads in mind, and default terms often leave teams exposed on power allocation and expansion options.
Which Markets Offer the Best Bare Metal Colocation Options for AI
The markets with the deepest inventory of GPU-capable colocation capacity as of 2025 are Northern Virginia, Dallas, Chicago, Silicon Valley, Phoenix, and Amsterdam, based on available power density, carrier diversity, and provider concentration (Source: JLL, 2025). Phoenix and Dallas have attracted significant new GPU-ready capacity as power constraints have tightened in Northern Virginia and Silicon Valley. For teams with European data residency requirements, Amsterdam and Frankfurt offer strong interconnect density alongside a growing pool of high‑density facilities.
Should You Move AI Inference to Bare Metal?
The decision to move AI inference to bare metal depends on four measurable signals, an honest assessment of operational capacity, and a clear view of what hybrid AI infrastructure strategy looks like in practice for most mature teams.
The Four Signals That Indicate Bare Metal Is the Right Move
Teams should move AI inference to bare metal when four conditions are present: sustained GPU utilization above 50 to 60 percent across the current cloud deployment, a monthly inference spend where finance is treating it as a capital planning question rather than an operational line item (typically above $30,000 to $50,000 per month), latency requirements that shared cloud infrastructure consistently fails to meet at P99, and data handling constraints that restrict which environments can legally process the inference payload. A single condition is a reason to model the economics. All four together form a strong operational case.
Cloud vs. Bare Metal vs. Hybrid: A Plain-Language Decision Matrix
The right infrastructure model for production AI inference depends on traffic profile and organizational maturity, and for most teams the answer is neither pure cloud nor pure bare metal. Pure cloud is the correct default for teams with bursty traffic, models still being actively iterated, or GPU utilization below 40 percent. Pure bare metal suits teams with stable, high-utilization workloads, a dedicated infrastructure team, and compliance constraints that preclude shared environments. Hybrid architecture is the de facto model for most mature AI product teams: training and inference are split across environments, with training staying in cloud and baseline inference running on bare metal, while cloud GPU handles demand spikes and model A/B testing. A common pattern is serving 70 to 80 percent of steady-state traffic from bare metal while retaining cloud burst headroom for peaks.
Who Should Not Move to Bare Metal Yet
Teams should not move inference to bare metal if GPU utilization is below 40 percent, traffic is unpredictable or highly seasonal, the model is still being frequently retrained and redeployed, or the infrastructure team lacks bandwidth to own hardware operations alongside active product development. In these situations the operational overhead of bare metal outweighs the cost savings, and cloud remains the correct default.
How to Run a Bare Metal Pilot Before Full Commitment
A bare metal inference pilot should be scoped to a single model endpoint on one to four GPUs in a colocation facility, running for 90 days with the equivalent cloud deployment still active in parallel. The pilot should produce three outputs: a validated AI inference cost comparison using actual utilization data, a documented runbook for hardware failure scenarios, and a staffing assessment of the ongoing operational load. Only after those three outputs exist should a team commit to a full migration.
How Teams Source Bare Metal Colocation for AI Workloads
One approach teams use when sourcing GPU-ready colocation is to evaluate facilities across multiple providers and markets simultaneously rather than engaging providers sequentially. Inflect is a digital infrastructure marketplace where teams can search and compare colocation options across more than 6,000 facilities in over 100 countries without a sales call or an RFQ process. For teams evaluating multiple markets and power density requirements in parallel, the platform shortens the sourcing cycle and provides a baseline for direct provider negotiations.
Finding the Right Infrastructure for AI Inference
Inflect's marketplace provides instant pricing, making it straightforward to compare GPU-ready colocation options from Equinix, Digital Realty, NTT, QTS, Iron Mountain, CyrusOne, and hundreds of other providers.
Ready to source infrastructure for AI inference?
Search by power density, market, and connectivity requirements to match your inference workload's specific needs
Run side-by-side comparisons across providers without an RFQ or a sales call
Access free expert advisory from infrastructure specialists with direct knowledge of GPU-dense deployment requirements
About the Author

Haley Rogers
Content & Social Media Specialist
Haley Rogers is the Content & Social Media Specialist at Inflect, bringing over two years of experience in social media, marketing, and content strategy — including time at a fast-paced tech company before joining the Inflect team. She specializes in translating complex digital infrastructure topics into clear, engaging content, with a particular focus on blog writing and brand storytelling across channels.
Contact:
